- 11 次围观
2024-11-11 Hacker News Top Stories #
- OpenCoder 是一个开源和可复现的代码语言模型(LLM)家族,包括 1.5B 和 8B 基础模型和聊天模型,支持英语和中文两种语言。
- 该博客是一个关于纽约市地铁系统的博客,名为"Project Subway NYC",博客的主体内容包括介绍、绘图、车站布局等。
- 《Grim Fandango》是一款由 Tim Schafer 创作的冒险游戏,游戏结合了墨西哥的亡灵节和经典的黑色电影元素。
- Jaws 是一个实验性的 JavaScript 到 WASM 编译器,目标是实现 100% 的 JavaScript 规范。
- 音频分离项目旨在创建一个程序来将音乐分离成单独的乐器声音。
- Physical Intelligence(π)是一种新型的人工智能,旨在使机器人能够像人类一样理解和交互物理世界。
- 写书的最大好处之一是你将更深入地了解材料,即使不发布也值得。
- OpenID Connect 规范已被发布为 ISO/IEC 标准。
- Visprex 是一个轻量级的数据可视化工具,旨在加速您的统计建模和分析工作流程。
- LLMs 达到了收益递减点,继续增加模型的规模和训练数据,并不能带来相应的性能提升。
OpenCoder: Open Cookbook for Top-Tier Code Large Language Models #
https://opencoder-llm.github.io/
OpenCoder 是一个开源和可复现的代码语言模型(LLM)家族,包括 1.5B 和 8B 基础模型和聊天模型,支持英语和中文两种语言。OpenCoder 从头开始训练,使用 2.5 万亿个令牌组成的数据集,包括 90% 的原始代码和 10% 的代码相关的网络数据,达到顶级代码 LLM 的性能。
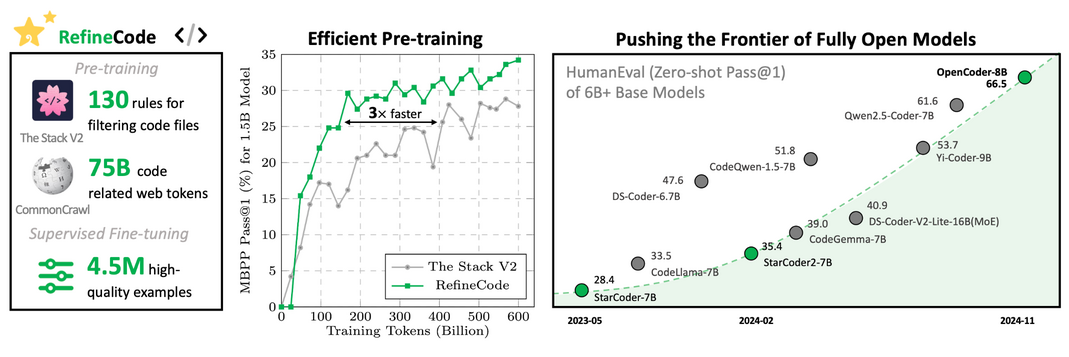
OpenCoder 提供了不仅仅是模型权重和推理代码,还包括可复现的训练数据、完整的数据处理管道、严格的实验消融结果和详细的训练协议。OpenCoder 致力于为研究人员提供一个开源的基础,推进代码 AI 的发展。
OpenCoder 的特点包括:
- 完全开源的代码 LLM,基于透明的数据处理管道和可复现的数据集,达到顶级性能
- RefineCode:一个高质量、可复现的代码预训练语料库,包含 9600 亿个令牌,覆盖 607 种编程语言
- 有意义的消融实验:旨在为代码 LLM 的各种设计选择和训练策略提供有意义的见解
- 发布的资源:包括最终模型权重、完整的数据处理管道、效率评估管道、可复现的预训练数据集、大规模 SFT 数据集和中间检查点
OpenCoder 的贡献者包括来自多个机构的研究人员,包括墨尔本大学、复旦大学、独立研究人员等。
HN 热度 562 points | 评论 71 comments | 作者:pil0u | 1 day ago #
https://news.ycombinator.com/item?id=42095580
- 该项目不仅发布了模型权重和推理代码,还提供了可复现的训练数据、完整的数据处理管道、严格的实验消融结果和详细的训练协议,对开放科学研究有益
- 这可能是最接近“开源”模型的情况
- 开源在机器学习领域中的含义与传统软件领域的开源有所不同,开源权重介于开源代码和二进制文件之间
- 开源权重意味着可以自由迭代以构建新事物,但需要源数据集合才能真正复现和修改
- 仅训练代码的模型可能无法理解人类的逻辑,导致生成的代码虽然看起来正确但对人类没有实际价值
- 该项目的模型在某些编程语言上的表现不如 Qwen2.5-Coder
- 许多顶级的开放大型语言模型来自中国,尽管中国在训练硬件上有一定限制
- 代码库中 75% 的文件完全重复,可能是由于仓库中的 forks 和 commits,而不仅仅是文件级别的复制粘贴
- 开源模型的权重和架构细节有助于学术界和开发者更好地理解和改进这些模型
NYC Subway Station Layouts #
http://www.projectsubwaynyc.com/gallery
这个网页是一个关于纽约市地铁系统的博客,名为"Project Subway NYC"。博客的主体内容包括以下几个部分:
- 首页:展示了博客的介绍和最新的更新。
- 关于:介绍了博客的创作者和博客的目的。
- 绘图:展示了纽约市地铁系统的各种绘图,包括地铁线路图、车站布局图等。
- 42nd Street Mega Station:专门介绍了纽约市地铁系统中最大的车站——42nd Street 站。
- 复杂连接:展示了纽约市地铁系统中一些复杂的换乘站。
- 复杂站:介绍了纽约市地铁系统中一些特殊的车站。
- X-Ray 区域地图:展示了纽约市地铁系统中一些车站的 X-Ray 区域地图。
- 车站布局:展示了纽约市地铁系统中一些车站的布局图。
- 地面零:介绍了纽约市地铁系统中一些特殊的车站。
- PATH:介绍了纽约市地铁系统中 PATH 线路的信息。
- PATH 换乘:展示了纽约市地铁系统中 PATH 线路的换乘信息。
- 照片:展示了纽约市地铁系统的各种照片。
- 3D 模型:展示了纽约市地铁系统的 3D 模型。
- 博客:展示了博客的文章和更新。
- 商店:展示了博客的商店信息。
- 服务:展示了博客的服务信息。
- 联系/提示:展示了博客的联系信息和提示信息。
HN 热度 303 points | 评论 98 comments | 作者:gregsadetsky | 1 day ago #
https://news.ycombinator.com/item?id=42096717
- 该项目的渲染质量令人印象深刻
- 网站使用了单页应用(SPA)技术,但未提供可书签的 URL,影响了资源的可用性
- 单页应用(SPA)可以通过使用
history.push来实现可分享的 URL - 网站的图片在移动端无法缩放,影响用户体验
- 网站的图片在桌面端也无法缩放,用户只能下载低分辨率图片
- 作者使用的是 Squarespace 提供的默认轻量级图库插件,这导致了缩放问题
- 通过长按图片并选择“在新标签中打开”可以实现缩放,但 iOS 用户无法这样做
- 一个名为 Exit Strategy 的应用程序可以帮助乘客根据转乘路线选择最佳车厢位置
- 新的 R211 列车配备了数字显示屏,显示即将到达的车站和车厢对应的出口
- 纽约地铁的旧列车缺乏基本的信息显示,如车站名称和线路图,这影响了乘客的使用体验
- 纽约地铁的旧列车和车站缺乏足够的信息显示,如线路图和列车到达时间,而广告牌却占据了大量空间
- 纽约地铁的用户体验较差,尤其是在理解快车停靠站和车站入口标识方面
- 纽约地铁的投资不足,导致列车和车站设施陈旧,但情况正在逐步改善
- 纽约地铁的管理存在问题,如工人效率低下和合同管理不当,导致建设和维护成本高昂
Grim Fandango #
https://www.filfre.net/2024/11/grim-fandango/
这个网页是一篇关于电子游戏《Grim Fandango》的文章。文章首先介绍了游戏的创作者 Tim Schafer,以及他如何在 1995 年夏天萌生了创作这款游戏的想法。 Schafer 想要结合墨西哥的亡灵节(Day of the Dead)和经典的黑色电影(film noir)元素,创作一款独特的冒险游戏。

文章接着描述了 Schafer 如何将游戏的设定从传统的 2D 像素艺术转变为 3D 图形。 Schafer 希望通过使用 3D 图形来创造更具电影感的游戏体验,并将玩家带入游戏世界中。然而,文章也指出,这个决定也是出于经济考虑,因为使用 3D 图形可以降低游戏的制作成本。
文章还提到了游戏的故事情节,包括主角 Manny Calavera 是一名死神,他的任务是将亡灵带到另一个世界。游戏的故事线受到经典电影《卡萨布兰卡》(Casablanca)和《唐人街》(Chinatown)的影响。
最后,文章提到了游戏的开发过程,以及 LucasArts 公司如何在游戏开发中使用 3D 图形技术。文章还指出,游戏的成功也使得 LucasArts 公司在之后的游戏开发中继续使用 3D 图形技术。
HN 热度 291 points | 评论 104 comments | 作者:cybersoyuz | 1 day ago #
https://news.ycombinator.com/item?id=42097261
- 游戏《Grim Fandango》中的谜题虽然有时困难,但并不令人感到混乱,整体上是一款杰作
- 评论者对游戏的批评可能带有偏见,认为只有像《猴岛小英雄》和《触手也疯狂》这样打磨得很好的游戏才值得称赞
- 游戏中的一些谜题设计得非常巧妙,但对玩家的操作要求较高,特别是时间限制的谜题
- 游戏的界面设计并不令人感到困扰,反而比一些需要精确像素操作的游戏更令人放松
- 《Grim Fandango》的世界观和主题对青少年玩家来说可能过于成人化,导致理解困难
- 尽管游戏内容对小孩来说难以完全理解,但这种神秘感反而增加了游戏的魅力,激发了好奇心
- 游戏中的成人世界和政治革命情节对青少年玩家来说非常吸引人,增加了游戏的特殊感
- 90 年代的游戏普遍对玩家不够宽容,频繁卡关是常见问题,但现代冒险游戏已经有所改进
- 有些谜题即使成年玩家也会感到困惑,例如电梯谜题,需要查找答案才能解决
- 与多人游戏不同,单人游戏中的“作弊”行为是可以接受的,尤其是在感到沮丧时
- 观看他人玩游戏有时比自己玩更有趣,尤其是当自己无法理解游戏时
- 游戏的某些部分对小孩来说可能过于复杂,但这种挑战有助于成长和理解成人世界
Show HN: Jaws – a JavaScript to WASM ahead-of-time compiler #
https://github.com/drogus/jaws
Jawsm 是一个 JavaScript 到 WebAssembly 编译器,使用 Rust 编写。它与其他编译器不同,生成的 WASM 二进制文件可以独立运行,而无需解释器。该项目仍在实验阶段,许多语言特性和内置类型尚未实现或不完整,但目标是实现 100% 的 JavaScript 特性。
项目背景 Jawsm 的作者在开发压力测试工具 Crows 时开始了这个项目,Crows 运行 WebAssembly 场景,但仅支持从 Rust 编译的代码。作者希望支持更多语言,尤其是像 JavaScript 这样的解释语言。然而,运行脚本语言在 WebAssembly 上并不理想,需要包含解释器或使用变种语言。
实现目标 Jawsm 的目标是使用现代 WebAssembly 提案实现 100% 的 JavaScript 特性,而无需编译解释器。作者认为,这是可能的,因为 WebAssembly 运行时已经是解释器。
当前状态 Jawsm 当前支持以下特性:
- 声明和赋值:var、let、const
- while 循环
- 字符串字面量、添加字符串字面量
- 数字和基本运算符:+、-、*、/
- 布尔值和基本布尔运算符
- 数组字面量
- 对象字面量
- new 关键字
- 闭包和作用域
- try/catch
- async/await(有限支持)
- Promise API(有限支持)
限制和未来计划 Jawsm 生成的二进制文件目前不兼容所有 WebAssembly 运行时,作者计划实现 WASIp2 和 WebAssembly GC。目前,作者使用 V8(通过 Chromium 或 Node.js)和 JavaScript polyfill 来开发。未来计划实现以下特性:
- 生成器和 await 关键字支持
- 完善语法和内置类型
- 支持更多 WebAssembly 运行时
使用方法 除非您想贡献代码,否则不建议使用 Jawsm。要使用 Jawsm,请克隆仓库并运行 execute.sh 脚本:
./execute.sh –cargo-run path/to/script.js
该脚本会生成 WAT 文件,编译成二进制文件,并使用 Node.js 运行。需要 Rust 的 cargo、wasm-tools 和 Node.js v23.0.0 或更新版本。
HN 热度 272 points | 评论 102 comments | 作者:drogus | 1 day ago #
https://news.ycombinator.com/item?id=42095879
- Jaws 是一个实验性的 JavaScript 到 WASM 编译器,目标是实现 100% 的 JavaScript 规范
- Jaws 使用了最近标准化的 WASM GC 和异常处理等特性,使得实现某些 JavaScript 语义(如作用域/闭包)相对容易
- 相比于 Porffor 和 Static Hermes,Jaws 的编译结果依赖于支持 WASM GC 和异常处理的运行时,目前只有 V8 和 WasmEdge 支持
- Wasmnizer-ts 编译 TypeScript 到 WASM GC,Jaws 未来计划支持 TypeScript 类型以进行类型优化
- Rust 语言虽然受到很多关注,但在某些地区(如爱沙尼亚)的就业市场上并不广泛使用
- 通过在公司内部逐步推广 Rust,可以从 C++ 项目中逐渐转向 Rust 开发
- Rust 语言在招聘方面具有优势,因为有很多人愿意从事 Rust 开发工作,但项目转向 Rust 需要时间
- WASM 可以实现廉价的请求隔离,比进程分叉更快,但当前的 JS 解释器在 WASM 上的性能仍然较差
Audio Decomposition – open-source seperation of music to constituent instruments #
https://matthew-bird.com/blogs/Audio-Decomposition.html
音频分离项目
该项目旨在创建一个程序来将音乐分离成单独的乐器声音。作者 Matthew Bird 最初的目标是创建一个程序来将音乐转换成乐谱,但他发现现有的开源算法不够简单和有效。
项目准备
该项目使用了爱荷华大学电子音乐工作室的乐器数据库。作者使用这些数据文件来计算每个乐器的 Fourier 变换和包络线。
工作原理
该程序使用两种方法来分离音乐中的乐器声音:Fourier 变换和包络线分析。
- Fourier 变换:程序每 0.1 秒对音乐文件进行 Fourier 变换,得到一个频谱图。然后,它使用存储的每个乐器的 Fourier 变换来重建音乐文件在该时间点的频谱图。
- 包络线分析:程序首先计算音乐文件的包络线,然后将其与每个乐器的包络线进行比较,以确定哪个乐器在播放哪个音符。
结果
作者表示,该程序工作得相当好,可以用来改进乐谱的重建,特别是对于那些难以找到正确音调或和弦的音乐。该程序运行速度也相对较快。
联系方式
作者 Matthew Bird 的联系方式可以在网页底部找到。
HN 热度 252 points | 评论 52 comments | 作者:thunderbong | 19 hours ago #
https://news.ycombinator.com/item?id=42098491
- 项目标题容易引起误解,实际是音高检测算法并分类乐器,而非源分离
- 作者还在高中,但已展现出令人惊叹的才能
- 音频源分离是研究中的通用术语,而茎分离是指分离音频茎,适用于多乐器音乐
- 当前的茎分离技术尚未完全成熟,分离出的乐器音轨质量仍有待提高
- 钢琴转 MIDI 的准确性已经非常高,即使音频质量较低也能表现良好
- 复杂多乐器作品和音效的音频转 MIDI 面临更多挑战,连续弦乐器如吉他难以准确捕捉
- 音频转 MIDI 存在已知的缺陷,人类听觉转录的速度远超编程转录
- 从 MIDI 数据导出准确的乐谱也是一个难题,尤其是持续时间和力度的可靠性
- 现代乐谱写作考虑了 MIDI,这可能使 MIDI 转乐谱变得相对容易,但仍有很多低级错误需要解决
Physical Intelligence’s first generalist policy AI can finally do your laundry #
https://www.physicalintelligence.company/blog/pi0
Physical Intelligence(π)是一种新型的人工智能,旨在使机器人能够像人类一样理解和交互物理世界。

π0 是该项目的第一个成果,一个通用型机器人基础模型,可以控制多种机器人,执行各种任务。π0 通过互联网规模的视觉语言预训练、开源机器人操作数据集和自有数据集训练而成,包含 8 种不同机器人的数据。该模型可以执行多种任务,包括折叠衣服、装箱、插电等。π0 的训练数据包括多种任务,每个任务都有不同的运动原语、物体和场景。
该模型的目标是提供一个通用的物理智能基础,能够让机器人像人类一样理解和交互物理世界。π0 的训练方法包括继承互联网规模的语义理解、增强预训练模型以输出连续动作、并通过流匹配进行训练。该模型可以通过微调来专门解决特定的任务。
HN 热度 197 points | 评论 176 comments | 作者:Terretta | 20 hours ago #
https://news.ycombinator.com/item?id=42098236
- 家务自动化可以提高人们的生活满意度,释放更多时间
- 女性加入劳动力市场并未给经济带来预期的提升,反而导致工资下降和更多无意义的工作
- 现在需要两个工资来维持家庭生活,这使得在家照顾孩子成为更难的选择
- 资本主义结构下,生产力提高和工作时间增加并未长期惠及工人
- 儿童由托儿所工作人员而非父母抚养,这可能是一个负面现象
- 社会价值衡量体系存在问题,应先解决这个问题再考虑用资本替代更多劳动力
- 选择权等同于财富,市场会通过提高价格来抵消工人收入的增加
- 星巴克等连锁咖啡店的兴起反映了社会对便利性的追求,但也可能导致传统咖啡文化的丧失
- 家务机器人的普及可能类似于历史上其他技术进入家庭的过程,最终使生活更加舒适
- 咖啡制作是一项简单技能,不应过度依赖连锁咖啡店提供的服务
You too can write a book #
https://parentheticallyspeaking.org/articles/write-a-book/
你也可以写一本书!
本文主要针对学者,旨在告诉大家两件事:你可以写一本书,你应该写一本书。
如果你不是使用别人的教科书,而是自己组织思想,那么你就已经写了一部分内容。写书的差距并不像你想象的那么大。一个小提示:学生在课前阅读的内容通常不超过六页,一旦超过八页,他们就不会读了。这意味着你只需要写四到六页的内容就可以了。
你应该写一本书
写书的动机有很多,但可能需要时间。把它当作对自己的长期投资吧。首先,你相信自己的世界观,并且正在努力推广它。你的书将成为他人下载你脑海的方式。其他地方的人可能会使用你的书,或者至少会把它放在阅读清单上。即使只有一个学生读了并理解了你的书,他就会带着你的想法前行。
当前的教科书可能不够好,特别是在编程语言领域。所以,写一本好的书来取代它们是很有必要的。如果你使用的是标准教科书,那么你可能已经知道应该教什么。谁会使用教科书?那些不确定的人。所以,我们需要帮助他们。
有时我们有资源——比如软件——但很多人不知道如何使用它们。例如,Racket 的 #lang 特性是教学编程语言的强大工具,但很多人还不知道。
写书的技巧
不要去商业出版社,他们要么不适应现代世界,要么会把你的工作付费墙。出版免费在线版本,特别是对于来自贫穷国家的移民来说,这是很重要的。上传你的文件到打印服务,甚至加上标记,它仍然会比商业出版社的书便宜。
在 STEM 领域,你的晋升案例不会依赖于来自 MIT 出版社的合同。获取合同相对容易,影响力才是难得的。优化它。每年发布一个新版本,不要陷入持续发布的陷阱。发布永久链接,不要破坏别人的构建。让人们容易地发送纠正意见。提供 PDF 和 HTML 格式的材料。
HN 热度 192 points | 评论 68 comments | 作者:azhenley | 1 day ago #
https://news.ycombinator.com/item?id=42096915
- 写书的最大好处之一是你将更深入地了解材料,即使不发布也值得
- 写书过程中获取高质量反馈很难,使用 Google 表单收集读者反馈很有帮助
- 写书可以使用 Markdown、LaTeX 等工具,选择自己熟悉的工具
- Typst 是一个很好的写书工具,但不支持 Doc 导出
- 写书需要两倍的自律:一是实际写作,二是决定完成
- 写书比想象中更难,很多人高估了自己的写作能力
- 博客是写书的第一步,但写书更令人印象深刻
- 博客可以作为写书前的练习,通过博客建立读者群
- 写书可以获得收入,而博客通常没有直接收益
- 写书的挑战不仅在于写作,还在于最终发布
- Leanpub 是一个很好的电子书出版平台,可以轻松发布到 Amazon 的印刷版本
- 写书标题应更准确地描述内容,如“你也可以写教科书”
OpenID Connect specifications published as ISO standards #
https://self-issued.info/?p=2573
OpenID Connect 规范已发布为 ISO 标准

OpenID Connect 规范已被发布为 ISO/IEC 标准。这些标准包括:
- ISO/IEC 26131:2024 — 信息技术 — OpenID Connect — OpenID Connect 核心 1.0(包含 errata Set 2)
- ISO/IEC 26132:2024 — 信息技术 — OpenID Connect — OpenID Connect 发现 1.0(包含 errata Set 2)
- ISO/IEC 26133:2024 — 信息技术 — OpenID Connect — OpenID Connect 动态客户端注册 1.0(包含 errata Set 2)
- ISO/IEC 26134:2024 — 信息技术 — OpenID Connect — OpenID Connect RP 初始化注销 1.0
- ISO/IEC 26135:2024 — 信息技术 — OpenID Connect — OpenID Connect 会话管理 1.0
- ISO/IEC 26136:2024 — 信息技术 — OpenID Connect — OpenID Connect 前端注销 1.0
- ISO/IEC 26137:2024 — 信息技术 — OpenID Connect — OpenID Connect 后端注销 1.0(包含 errata Set 1)
- ISO/IEC 26138:2024 — 信息技术 — OpenID Connect — OAuth 2.0 多响应类型编码实践
- ISO/IEC 26139:2024 — 信息技术 — OpenID Connect — OAuth 2.0 表单发布响应模式
这些标准的发布将促进 OpenID Connect 的更广泛采用,特别是在需要使用国际标准组织认可的规范的地区。
OpenID 基金会计划提交更多的规范家族,包括 FAPI 1.0 规范、eKYC-IDA 规范和 FAPI 2.0 规范。
HN 热度 191 points | 评论 66 comments | 作者:mooreds | 6 hours ago #
https://news.ycombinator.com/item?id=42101181
- OpenID Connect 主要关注身份验证,而 OAuth 关注授权
- OpenID Connect 是在 OAuth 的基础上构建的,而不是重新发明身份验证流程
- OAuth2.1 收紧了 OAuth2 的一些灵活性,但很少有人知道其存在
- OpenID Connect 解决了 OAuth2 的“狗窝”批评,理论上不再需要为每个提供商编写自定义模块
- OAuth 通常与 Google、Facebook 等账户关联,用于在其他系统中代表用户执行操作
- 纯授权的情况很少见,大多数情况下授权与身份验证同时进行
- OpenID Connect 通过添加身份验证信息和定义的声明,扩展了 OAuth 的功能
- ISO 标准需要付费获取,这是一件坏事,且标准设计和实现应减少时间消耗
- 尽管 ISO 标准需要付费,但 OpenID Connect 和 OAuth 的标准本身是免费公开的
Show HN: Visprex – Open-source, in-browser data visualisation tool for CSV files #
Visprex 是一个轻量级的数据可视化工具,旨在加速您的统计建模和分析工作流程。其主要特点包括:
快速:您可以在几秒钟内可视化数据,快速建立对数据集的直观感受。 安全:您的数据完全在浏览器中处理,这意味着您的数据不会被发送到任何地方。 开源:源代码完全开源,托管在 GitHub 上。
Visprex 适合以下人群:
学生:Visprex 适合正在学习统计建模的学生,不需要启动计算环境或编写繁琐的可视化脚本。 数据科学家:Visprex 也适合数据分析师,他们可以快速检查表格数据,而不用担心数据隐私或个人身份信息(PII),因为数据不会离开浏览器。
快速入门:
- 加载您的数据集
- 了解特征分布
- 可视化线性关系
- 检查特征之间的相关性
Visprex 是一个免费、开源的工具,源代码托管在 GitHub 上,网站地址是 visprex.com。
HN 热度 179 points | 评论 24 comments | 作者:kengoa | 1 day ago #
https://news.ycombinator.com/item?id=42096837
- 该工具在处理 CSV 文件格式问题上不如 Excel 灵活,建议使用 Notepad++ 等工具预先检查文件格式
- 计划增加数据清洗功能,如快速切换不同策略处理数据,包括字符处理、缺失值填充、日期解析等
- 已开源一个模糊去重工具,未来可能扩展到更广泛的数据清洗
- 建议增加对 xlsx 等其他数据格式的支持,并改进当前的 CSV 解析器
- 推荐使用 dayjs 库处理各种日期格式,简化日期解析过程
- 项目中存在一些拼写错误,已提交修复
- 日期/时间列目前不被识别为数值列,导致无法生成散点图,计划改进解析器以支持更多数据类型
LLMs have reached a point of diminishing returns #
https://garymarcus.substack.com/p/confirmed-llms-have-indeed-reached
LLMs 达到了收益递减点
文章作者 Gary Marcus 讨论了大型语言模型 (LLMs) 的发展现状。Marcus 指出,尽管 LLMs 在近年来取得了巨大的进步,但它们已经达到了收益递减点。也就是说,继续增加模型的规模和训练数据,并不能带来相应的性能提升。

经济影响
Marcus 预测,这将对 LLMs 的经济产生重大影响。目前,许多公司的估值都基于 LLMs 将成为通用人工智能的想法。但是,如果 LLMs 的性能提升速度放缓,投资者可能会失去信心,导致估值下降。同时,LLMs 的训练成本也会增加,导致利润空间缩小。
社会影响
Marcus 也指出,LLMs 的发展现状对社会也有影响。许多人已经对 LLMs 产生了过高的期望,并且忽视了其局限性。同时,LLMs 的发展也导致了其他人工智能方法的忽视,可能会导致美国在人工智能领域落后于其他国家。
结论
Marcus 总结道,LLMs 的发展现状表明,它们已经达到了收益递减点。虽然 LLMs 仍然有用,但它们不太可能成为通用人工智能。为了实现可靠的人工智能,需要回到起点,重新思考人工智能的基础方法。
HN 热度 127 points | 评论 137 comments | 作者:signa11 | 22 hours ago #
https://news.ycombinator.com/item?id=42097774
- 2010 年代深度学习的繁荣是由于增加层数和数据量,但最终也遇到了收益递减的问题,LLM 同样会遇到这种情况。
- 长期来看,当前的 LLM 状态将促进遗留应用程序向对话 API 的迁移,形成新的经济机会。
- 对于那些基于快速永恒增长承诺投资的人来说,LLM 的收益递减可能不是好事。
- 市场会惩罚那些对技术理解有误或缺乏理解的人,这是合理的。
- 市场的过度修正通常会影响到更广泛的群体。
- 通过数据筛选、生成数据和增加推理时间,LLM 已经多次克服了收益递减的问题。
- Gary Marcus 反对纯神经网络 AI,尤其是在需要可靠性的 AGI/ASI 场景中,他支持混合神经符号 AI。
- Marcus 的批评主要集中在神经网络的缺点上,而没有提供足够的实质性和前沿的研究支持。
- 无人质疑神经网络在重采样先前接触过的数据方面可以超越人类,数字孪生和辩论也是如此。
- 目前还没有能够完全自主完成家务的机器人,这与 LLM 的讨论无关。
- 有些评论者认为 Marcus 的观点过于片面,缺乏自我反省和诚实。
- 神经网络已经有一些尝试,如神经图灵机和可微分神经计算机,但 Marcus 的文章缺乏足够的实质内容。
- Marcus 的观点可能会影响政府决策,因此他的言论需要更加谨慎。