- 3 次围观
2024-07-05 Hacker News Top Stories #
- .DS_Store 文件源于1999年苹果重写Finder时引入的Desktop Services,用于存储文件系统配置,同时文章探讨了Mac文件系统中资源fork的概念及其问题。
- 黑客组织ShinyHunters泄露了Twilio旗下Authy应用3300万用户的电话号码,尽管Twilio采取了安全措施,仍提醒用户更新软件以加强防护。
- Xcapture-BPF是一套基于eBPF的Linux性能分析工具,提供类似top的视图但具有更深度的系统洞察力,帮助用户识别和解决性能瓶颈。
- 文章讨论了AI领域6000亿美元的问题,指出AI基础设施投入与实际收益之间的差距,强调创造用户价值的公司才能获得回报。
- 阅读难以理解的书籍能激发思考与探索,即使理解不完全,也能从中获得乐趣和启示。
- 通过优化和并行化C代码,可以在150行代码中实现超越NumPy的矩阵乘法性能,达到1TFLOPS的峰值表现。
- 一位开发者分享了自己耗费两年时间开发应用却因竞争对手先行成功而放弃的故事,强调"Just Ship It"的重要性和避免过度追求完美的教训。
- Jeffrey Snover创建的PowerShell革新了Windows管理方式,尽管面临内部阻力,最终成为关键工具并推动了Microsoft向云计算的转型。
- Firezone采用Rust的sans-IO设计理念构建安全远程访问服务,通过纯状态机协议实现高效网络服务,提高了数据传输安全性。
- 在Haskell中利用Huffman编码实现数据压缩工具,文章涵盖编码原理、Huffman树构建及实际文件压缩实践,探讨了性能优化策略。
The Origins of DS_store (2006) #
https://www.arno.org/on-the-origins-of-ds-store
这篇文章讲述了 DS_store 文件的起源。在 1999 年,苹果公司的技术主管在重新设计 Mac OS X Finder 时,决定从头开始重写 Finder。
在这个过程中,他们将 Finder 的用户界面和核心功能进行了分离,后端负责文件枚举、监控文件系统变化、处理元数据等工作。这两个组件被称为 Finder_FE 和 Finder_BE(前端和后端)。
为了将 Finder 后端用于 Finder 之外的其他用途,他们计划将其作为公共 API 发布。因此,他们决定将其命名为“Desktop Services”(桌面服务),并在文件名前加上“.”,使其在 Unix 操作系统中被视为不可见文件,包括 Mac OS。
因此,.DS_Store 的名称就是“Desktop Services Store”。文章还提到了一个至今未修复的 bug,导致会过度创建.DS_Store 文件。此外,Desktop Services API 仍未完全发布。
HN 热度 414 points | 评论 217 comments | 作者:edavis | 1 day ago #
https://news.ycombinator.com/item?id=40870357
- Mac 文件系统中的“fork”概念引起了一些困惑,资源和数据组件存在成对,一个是元数据,一个是文件内容。
- Mac 应用程序通常将所有数据存储在资源 fork 中,类似于 Berkeley DB,性能差,但在文件较小、磁盘开销低且部署容易时能胜任。
- Mac 文件系统中的资源和数据组件存在,分别是元数据和文件内容。
- Unix 中的元数据存储在目录块 inode 中,而不是唯一地与文件绑定。
- 资源管理器将 MFS 磁盘视为每个文件都包含资源的单一文件堆栈。
- 早期 MacOS 中的资源结构限制了将其映射到 inode 中的可能性。
- 资源 fork 使早期 Mac 可以轻松处理 128kb 和大量磁盘交换。
- 许多经典 Mac 应用程序将所有数据存储在资源 fork 中,性能较差但部署简单。
- 资源 fork 存储了可用于编辑的各种内容,如图标、GUI 资源和文本。
- 资源 fork 仍然在 APFS 中存在,用于实现文件和目录的自定义图标。
- MacOS X 捆绑包实际上是 NeXTStep 捆绑包的延续。
- 资源 fork 中存储的可执行代码段构成了应用程序的主体。
Twilio confirms data breach after hackers leak 33M Authy user phone numbers #
Twilio 确认数据泄露,黑客泄露了与 Authy 应用程序相关的 3300 万个电话号码。ShinyHunters 黑客在六月底在重新启动的 BreachForums 网站上宣布,他们正在泄露与 Twilio 的两步验证应用程序 Authy 相关的 3300 万个随机电话号码。泄露的信息还包括与 Authy 用户相关的帐户 ID 和一些其他非个人数据。

Twilio 在其网站上发布的安全警报中确认了数据泄露。Twilio 表示:“由于未经身份验证的端点,Twilio 已经检测到威胁行为者能够识别与 Authy 帐户相关的数据,包括电话号码。我们已采取措施保护此端点,并不再允许未经身份验证的请求。”Twilio 没有发现黑客进入其系统或获取其他敏感数据的证据,但作为预防措施,建议 Authy 用户安装最新的 Android 和 iOS 安全更新。
Twilio 表示:“虽然 Authy 帐户没有受到影响,但威胁行为者可能会尝试使用与 Authy 帐户相关的电话号码进行钓鱼和短信钓鱼攻击;我们鼓励所有 Authy 用户保持警惕,并对他们收到的短信保持高度警惕。”
HN 热度 386 points | 评论 205 comments | 作者:mindracer | 11 hours ago #
https://news.ycombinator.com/item?id=40874341
- 手机号码泄露问题引发了对传统电话网络未来的担忧,呼吁解决垃圾电话问题以避免电话网络沦为传真机命运。
- 医生、牙医等重要电话通知对一些人至关重要,呼吁立法阻止虚假电话,以免影响生命。
- 一些人仍频繁使用电话,特别是商务人士,强调电话仍是重要沟通方式。
- 对于垃圾电话问题,建议使用第二张 SIM 卡,限制第二号码的使用范围。
- 垃圾电话问题可能与联系人下载垃圾应用有关,呼吁加强隐私保护。
- 建议使用新的、非本地号码以减少垃圾电话,但可能会导致被误认为垃圾电话。
- 社会服务、医生、牙医等重要电话通知对弱势群体至关重要,呼吁改善通信系统以保障服务。
- 垃圾电话问题导致人们不愿接听电话,使用 FaceTime 等替代传统电话通话。
- 垃圾电话问题对医疗服务等领域造成困扰,呼吁加强监管。
- 针对 Twilio 数据泄露事件,呼吁对公司采取严厉惩罚以提高数据保护意识。
Show HN: Xcapture-BPF – like Linux top, but with Xray vision #
网站 https://0x.tools/ 是一个针对 Linux 系统的性能分析工具集,旨在简化部署并减少系统故障排除的摩擦。该工具集不需要升级操作系统、安装内核模块、重量级监控框架、Java 代理或数据库。它允许您测量单个线程级别的活动,如线程执行的代码、睡眠状态、系统调用和内核等待位置,通过跟踪(而非追踪)并在适当的时间对正确的事件进行采样。
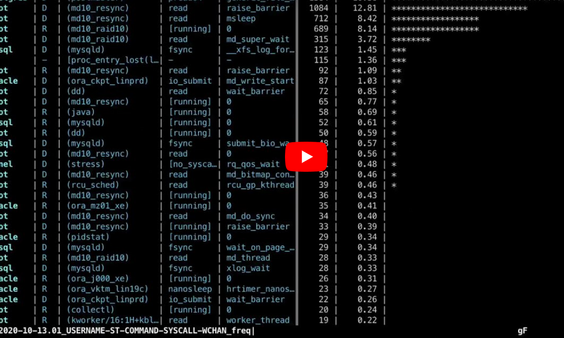
工具包括 xcapture-bpf 和 xtop,类似于 Linux top 工具,但具有 X 射线视觉和查看性能数据的能力。您可以用它进行系统级概览,并深入了解单个线程的活动,甚至是单个内核事件,如锁等待或内存停顿。xcapture-bpf 目前仍处于测试阶段,不建议在繁忙的生产系统上运行。
它使用 eBPF 技术,需要至少 RHEL 8.1 或 Ubuntu 24.04。如果您尝试在其他发行版/平台/版本上运行,请告诉作者结果。安装 xcapture-bpf 需要一些先决条件,如安装 bcc、bcc-tools、python3 和 python3-bcc。您可以通过克隆 GitHub 存储库和运行相应命令来安装。xcapture-bpf 仍在不断发展,作者计划充分利用 eBPF 的可编程性。
此外,工具还包括 psn、schedlat 等实时交互式工具和低开销线程活动采样器,可用于生产系统的始终开启低频率性能分析。这些工具旨在帮助您系统地排查 Linux 系统的性能问题。
HN 热度 372 points | 评论 37 comments | 作者:tanelpoder | 1 day ago #
https://news.ycombinator.com/item?id=40869877
- 使用 BCC 工具调试生产问题,发现大量环回设备导致页面缓存压力,启用直接 io 解决问题,eBPF 让你做不可思议的事情。
- 学习 BCC/bpftrace 调试客户系统内存泄漏问题,非常有用。
- 容器通过创建循环设备提供块存储,发现循环块设备 I/O 等待占用 60% 核心,通过 BCC 工具发现问题在循环块设备而非底层 NVME,启用直接 io 后解决问题。
- 曾遇到类似问题,编写小型守护进程跳过页面缓存,解决问题。
- CSI 提供循环设备,使用 containerd,启用直接 io 可禁用双重缓存。
- eBPF 基于 OpenTelemetry 开源的低开销连续分析代理可能对用户有用。
- 采样分析中捕获调用栈费用如何?使用 Intel CET 技术可以捕获阴影栈,但是否会使用?
- 调度切换 tracepoint 是热点事件,堆栈采样会增加开销,但对大多数工作负载足够。
- DTrace 与 eBPF 不同,各有不同目标和方法,DTrace 在 Linux 上被 eBPF 取代,但两者各有所长。
- 在 Linux 中为跟踪和可观察性使用 DTrace 还是 eBPF?eBPF 可做 DTrace 不能的事情,如 Cilium。
- DTrace 在 Oracle Linux 上支持,但在 Linux 上是编译为 eBPF 的脚本前端。
- eBPF 在 Linux 上自动处理现有和新进程,DTrace 也可以。
- XDP 子系统设计用于在数据到达网络堆栈之前对网络数据应用过滤器,但性能不及 DPDK。
- 作者使用 BCC 工具解决问题,计划使用 libbpf 作为目标。
- BCC 有限制,Ubuntu 22.04 存在 BCC/内核头文件不匹配问题,libbpf 与 CO-RE 解决这些问题。
- 作者构建简单追踪事件,保证线程安全。
- XDP 传递数据包指针给 BPF 代码,绕过内核堆栈完全。
AI’s $600B Question #
https://www.sequoiacap.com/article/ais-600b-question/
这篇文章讨论了人工智能(AI)领域的发展现状,特别关注了 AI 基础设施建设与实际收入增长之间存在的巨大差距。文章指出,自 2023 年 9 月发表了“AI 的 2000 亿美元问题”以来,人们对 AI 领域的收入情况一直持续关注。最近,Nvidia 成为了全球市值最高的公司,引发了人们对 AI 领域的进一步思考。
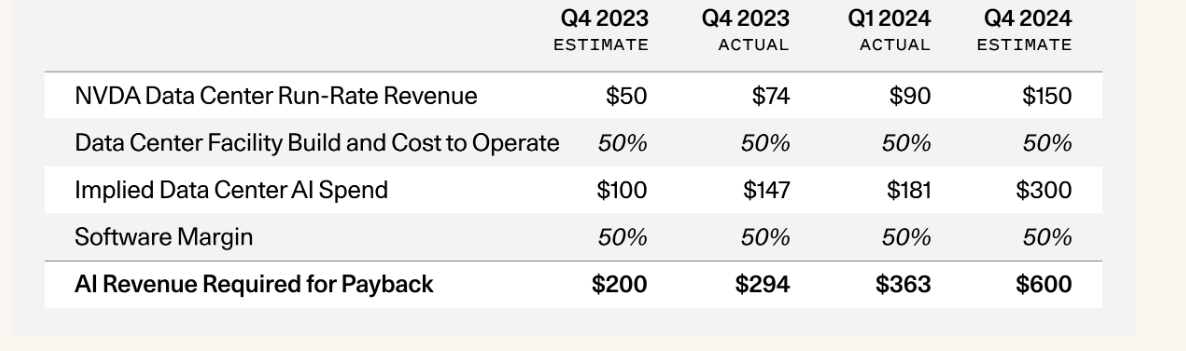
作者提出了“AI 的 6000 亿美元问题”,通过对 Nvidia 的营收预测进行分析,得出了这一数字。文章指出,自 2023 年以来发生了一些变化,包括 GPU 供应短缺问题得到缓解,GPU 库存增加,以及 OpenAI 仍占据 AI 收入的主导地位等。
此外,文章还讨论了 AI 领域的投资情况,指出了一些潜在的风险,如缺乏定价权、投资浪潮可能导致资本的过度消耗以及技术的快速折旧等。作者认为,AI 领域将创造巨大的经济价值,专注于为最终用户提供价值的公司将获得丰厚回报。
总的来说,文章强调了 AI 领域的潜力和重要性,同时提醒人们在投资和发展过程中保持清醒头脑,认识到 AI 技术发展的道路可能会充满挑战,但也必将是值得的。
HN 热度 342 points | 评论 505 comments | 作者:fh973 | 1 day ago #
https://news.ycombinator.com/item?id=40869461
- 有人认为 AI 公司的核心模型将被大规模商品化,利润边际接近 0,尤其是如果微软和 Meta 继续免费提供这些模型。
- 有人认为 AI 公司正在全力以赴,就像他们为元宇宙玩法所做的一样,但结果并不理想。
- 有人认为虚拟现实技术的改进不会促使人们购买,因为人们更喜欢在现实生活中做事情。
- 有人认为 VR 需要太多设置,社交方面也存在问题,成本高,体验受限。
- 有人认为 VR 需要更多的硬件支持,如 VR/存储等房间,但目前的住房短缺可能会影响未来的 VR 发展。
- 有人认为 VR 不会成为主流,直到解决人们更喜欢在现实生活中做事情的基本问题。
- 有人认为 VR 需要更多的舒适性突破和更高的分辨率,以推动行业发展。
- 有人认为 VR 可能会在现实生活变得糟糕时迎来爆发。
- 有人认为在线游戏、社交媒体和智能手机等技术已经证明人们更倾向于虚拟而非现实生活。
- 有人认为共享体验是 VR 成功的关键,例如共同游戏或观看内容,以及在 AR 或 VR 空间中与他人互动。
- 有人认为人们对 VR 的偏好问题不是主要问题,而是舒适性和内容限制。
- 有人认为 VR 公司需要提供更多的共享体验,以吸引更多用户。
- 有人认为 VR 公司需要解决舒适性和内容问题,以推动行业增长。
- 有人认为 VR 公司需要关注硬件和软件的综合发展,以提升用户体验。
- 有人认为 VR 公司需要创新,以吸引更多用户并推动行业发展。
- 有人认为 VR 公司需要关注用户需求,以确保产品的成功。
- 有人认为 VR 公司需要不断改进,以满足用户的需求和提升产品质量。
- 有人认为 VR 公司需要关注内容和用户体验,以吸引更多用户并保持竞争力。
The joy of reading books you don’t understand #
https://reactormag.com/the-joy-of-reading-books-you-dont-entirely-understand/
这篇文章谈到了阅读那些自己并不完全理解的书籍所带来的乐趣。作者分享了自己阅读一本历史繁复的书时的经历,虽然对书中的历史细节并不完全理解,但通过查阅资料,作者开始享受这个过程,将阅读与探索历史联系在一起。

文章还提到了现在出版界更注重畅销书和品牌效应,但仍有许多具有挑战性和神秘感的书籍出版。作者呼吁读者们在有限的阅读时间里也尝试阅读那些让人感到困惑或不太理解的书籍,因为其中也蕴含着乐趣和启发。
最后,作者强调了对于不完全理解一本书却喜爱它的态度是完全正常和可接受的,也提倡在阅读过程中保持开放心态,欢迎不确定性,给予那些奇特或令人困惑的书籍一个机会。
HN 热度 335 points | 评论 213 comments | 作者:speckx | 1 day ago #
https://news.ycombinator.com/item?id=40870280
- 有人认为阅读书籍应该唤醒内心深处的冰封之海,挑战我们的信念,带来新的视角和思考,而非仅仅让我们感到快乐。
- 有人认为阅读应该让人快乐,反对认为阅读应该带来震撼和痛苦的观点。
- 有人主张在阅读复杂书籍时不要担心背景知识和笔记,而是通过沉浸式阅读获得更好的理解和享受。
- 有人分享了阅读《无尽的玩笑》时未做笔记,错过了主要情节,但仍然喜爱这本书的经历。
- 有人建议重新阅读《无尽的玩笑》,并推荐使用 Infinite Jest Wiki 上的页面注释作为参考。
- 有人认为阅读复杂书籍时应该采取主动避免笔记和背景材料的习惯,沉浸式阅读是理解的关键。
- 有人分享了阅读《无尽的玩笑》时没有做笔记,错过了主要情节,但喜欢这种体验,认为第二次阅读比第一次更令人愉悦。
- 有人提到了在阅读技术性书籍时频繁查阅词典和维基百科,以便更好地理解内容。
- 有人分享了对于阅读不理解的书籍的喜爱,认为即使不理解也能享受阅读过程。
- 有人认为阅读书籍应该让人理解,而不是仅仅产生联想和情感,强调理解的重要性。
- 有人分享了阅读《蓝色火星》时对政治体系的理解,以及阅读书籍对认知和理解的影响。
- 有人提到了阅读书籍时的个人体验和成长,以及对书籍中不理解部分的回顾和欣赏。
- 有人分享了对于阅读不理解的书籍,随着时间慢慢领悟和理解的经历。
- 有人认为在阅读过程中,有时需要放慢脚步,理解书籍的路径,甚至需要寻找其他书籍来获得更多背景知识。
- 有人讨论了东方和西方对于理解的不同观念,以及现代电影对于观众理解的处理方式。
- 有人分享了对于电影中不理解情节的体验,以及推荐了一些冷战间谍惊悚片。
- 有人认为现代电影为了吸引观众,必须在揭示情节之前让观众认为他们理解了,否则观众可能会失去兴趣。
- 有人分享了对于电影中情节不明确的体验,以及对于电影中推理和理解的欣赏。
- 有人提到了在观看电影时保持对情节的不了解,以便体验故事的过程和转折。
- 有人讨论了现代电影对于观众理解的处理方式,以及对于观众自主思考和体验的重要性。
- 有人分享了对于复杂书籍的阅读体验,以及对于理解和享受阅读的看法。
- 有人认为阅读书籍应该让人理解,而不是仅仅产生联想和情感,强调理解的重要性。
- 有人分享了对于阅读不理解的书籍的喜爱,认为即使不理解也能享受阅读过程。
Beating NumPy matrix multiplication in 150 lines of C #
https://salykova.github.io/matmul-cpu
这个网页内容主要介绍了如何在 CPU 上实现高性能矩阵乘法,以及如何优化和并行化 C 代码,以实现与 NumPy 相媲美的性能。作者试图在保持代码简单、可移植和可扩展的同时,实现高性能的矩阵乘法。实现遵循 BLIS 设计,适用于任意矩阵大小,并在 AMD Ryzen 7700(8 核)上进行了优化,实现了超过 1 TFLOPS 的峰值性能。

文章首先介绍了矩阵乘法在现代神经网络中的重要性,以及 NumPy 等库如何利用外部 BLAS 库来实现高度优化的线性代数运算。作者挑战自己,尝试在不深入汇编和 Fortran 代码的情况下,为自己的 CPU 编写高性能的矩阵乘法。通过阅读有关快速矩阵乘法的教程和论文,作者最终实现了一个性能出色的矩阵乘法算法,并与 NumPy 进行了比较。
文章详细介绍了从头开始实现矩阵乘法的过程,包括朴素实现、核心算法、缓存优化等内容。作者通过优化算法,利用 SIMD 指令和缓存管理,最终实现了高性能的矩阵乘法,并通过多线程并行化进一步提升性能。
最终,作者展示了实现的性能测试结果,证明了通过优化和并行化,可以实现与 NumPy 相媲美的高性能矩阵乘法。文章提供了详细的代码实现和性能评估,为读者深入了解矩阵乘法优化提供了有益的参考。
HN 热度 326 points | 评论 61 comments | 作者:p1esk | 1 day ago #
https://news.ycombinator.com/item?id=40870345
- 算法选择是否恰当是最重要的,能否消除一些工作?
- 可以消除与内核的往返和类似的繁重操作吗?
- 可以进行矢量化吗?通过重新组织数据,而不是使用结构体数组,可以获得相同的机器码。
- 可以优化缓存效率吗?如果已经重新组织为矢量,则可能已经处理,但在并行代码中,如果无法将数据隔离到一个线程(伪共享等),这可能会变得更加复杂。
- 可以利用硬件特定的其他功能吗?这可以是使用内部函数或手动编写汇编语言等。
- 网络的影响不容忽视,通过重新构造查询,可以显著提高性能。
- BLIS 存储库中引用的论文是了解这些内容的权威参考。
- 与 NumPy 2.0 的比较应该更好,因为它集成了 Google Highway 以实现跨不同微架构的更好 SIMD。
- 不应该将一侧负担在 Python 上,而另一侧是 C,可以进行苹果对苹果的比较,其中两侧都是用 C 编写,一个调用 BLAS 库,另一个调用另一种实现。
- Python 是正确的比较对象,因为它是在现代进行这些计算最流行的方式,特别是使用 NumPy。
- 如果您选择了数据科学领域的常见矩阵乘法方法(NumPy),性能与潜在理想参考实现相差多远?
- 作者需要为这种人为的比较受到批评。
- 与 NumPy 比较是混乱的,因为 NumPy 通常与其他 BLAS 实现一起使用,但作者没有妥善处理这一点。
The saddest “Just Ship It” story ever (2020) #
https://www.kitze.io/posts/saddest-just-ship-it-story-ever
这篇文章讲述了作者在开发一个应用过程中的经历。作者在 2018 年元旦开始构建这个应用,但在两年的开发过程中遇到了许多困难和挑战。他不断追求完美,总是觉得再加一个功能或一个屏幕就会让应用更好。然而,最终他却放弃了这个应用的开发,因为发现了一个竞争对手已经解决了他想要解决的问题,并且做得更好。
作者感到沮丧和失落,意识到自己浪费了大量时间。最终,他决定放弃这个应用,转而成为竞争对手的用户和粉丝。文章最后呼吁读者不要重蹈作者的覆辙,而是要勇敢地发布自己的产品,强调“Just Ship It”的重要性。
HN 热度 228 points | 评论 269 comments | 作者:thunderbong | 20 hours ago #
https://news.ycombinator.com/item?id=40872182
- 有时候软件工程师/架构师的价值在于技术细节,不应被“加速”,抵制“只是发布它”的压力,专注于专业工作,避免烧尽自己。
- 除非你拥有公司股份,否则不必确保公司最具盈利性,你的工作是创建优秀软件,而不是追求利润。
- 开发人员通常不会因为卓越成就而获得补偿,除非拥有公司的显著股份,为什么要付出一切却得不到回报?这是公平的吗?
- 工作在寻求平衡,要做出可用产品和及时产品之间的权衡,不要过度工程化,保持简洁。
- 工作不仅是为了自己,也是为了为用户带来价值,专注于有效地开发产品。
- 在小型和中型公司中,需要做出妥协,作为专业人士,要做出有利于业务结果的选择。
Jeffrey Snover and the Making of PowerShell #
https://corecursive.com/building-powershell-with-jeffrey-snover/
这篇文章讲述了 Jeffrey Snover 如何创建了 PowerShell,这是一种改变了 Windows 系统管理方式的命令工具。文章详细描述了 PowerShell 的发展历程,从最初的构想到最终的实现,以及在过程中遇到的挑战和困难。

Jeffrey Snover 通过坚定的信念和专注于长期目标,成功地推动了 PowerShell 的发展,并最终使其成为 Windows 系统管理的重要工具。文章还强调了 PowerShell 如何帮助 Microsoft 实现了向云端转型,为 Azure 的发展奠定了基础。Jeffrey Snover 的故事展示了如何在面对困难和批评时,保持专注和坚定,最终实现目标并取得成功。
HN 热度 228 points | 评论 216 comments | 作者:todsacerdoti | 12 hours ago #
https://news.ycombinator.com/item?id=40874013
- PowerShell 在 Windows 中面临极大阻力,Jeffrey Snover 因推动 PowerShell 而被降职。
- PowerShell 存在是因为 Windows 不是基于文件的,需要调用各种 API 并获取结构化数据。
- 希望 Microsoft 为 PWSH 添加基本 GUI 功能,简化用户界面和图表创建。
- PowerShell 7 与 PowerShell 5 不兼容,存在功能丢失,由于.NET 和 Windows 团队之间的冲突。
- Microsoft 生态系统似乎分为 WinDev 与 DevDiv 政治,Azure 业务单位下的 UNIX 式文化与 WinDev 的传统文化。
- PowerShell Core 是跨平台的,但某些 Azure 功能似乎只能通过 PowerShell 访问。
- PowerShell 在 Azure 云中表现出色,提供大量支持,使得使用 Python 不再必要。
- PowerShell 比 Bash 更具生产力和可读性,支持对象导向,适合创建管道。
- PowerShell 具有更多内置命令,少依赖外部命令,因此更少受到不匹配问题的影响。
- PowerShell 更适合 Azure 等任务,但对于小型任务,Bash 仍是首选。
- PowerShell 对于复杂任务更有用,但在简单任务上可能不需要其功能。
- PowerShell 比 Bash 更强大,但可能需要更多学习。
- PowerShell 在处理重要任务时表现出色,但在离开该领域后可能不再适用。
- PowerShell 在某些方面优于 Bash,但在其他方面可能令人困惑,因此个人偏好因人而异。
- PowerShell 比 Bash 更强大,但可能需要更多学习。
- PowerShell 在一些方面比 Bash 更有优势,但在其他方面可能令人困惑,因此个人偏好因人而异。
Sans-IO: The secret to effective Rust for network services #
https://www.firezone.dev/blog/sans-io
这篇博文介绍了在构建网络服务时如何使用 Rust 语言中的 sans-IO 设计。作者在 Firezone 使用 Rust 构建安全的远程访问服务,核心是一个名为 connlib 的连接库,用于管理网络连接和 WireGuard 隧道以保护流量。connlib 是使用 Rust 构建的,采用了 sans-IO 设计。在 sans-IO 设计中,协议被实现为纯状态机,避免了在多个地方通过套接字发送和接收字节。时间也被抽象化,每个需要知道当前时间的函数都接收一个 Instant 参数而不是自己调用 Instant::now。这种设计模式在 Rust 中被广泛使用,例如 quinn、quiche 和 str0m。
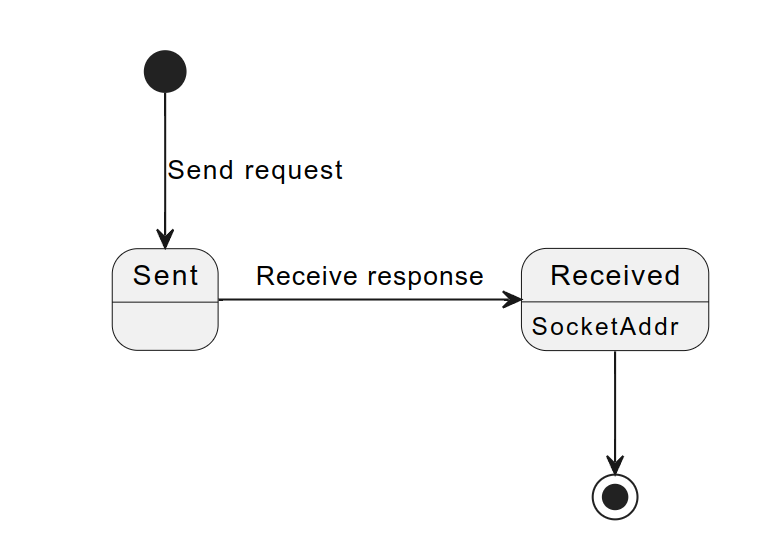
文章讨论了 Rust 的异步模型和“函数着色”辩论,以及如何将传统的 IO 设计转换为 sans-IO 设计的问题和原因。sans-IO 设计使得代码更易于组合、测试,并与 Rust 的特性很好地结合。文章还探讨了 sans-IO 设计的优点,包括易于组合、灵活的 API、易于测试、适应 Rust 的特性等。
最后,文章提到了 sans-IO 设计的一些缺点,如自己编写事件循环可能导致难以发现的微妙 bug,以及需要编写更多代码来处理顺序工作流等。尽管 sans-IO 设计在 Rust 社区中并不十分普遍,但它提供了一种新颖且有趣的编程方式,特别适合处理网络编程。
HN 热度 200 points | 评论 65 comments | 作者:wh33zle | 20 hours ago #
https://news.ycombinator.com/item?id=40872020
- 在 Rust 中,async 函数编译成状态机,每个
.await点代表不同状态的转换,使开发者能够轻松编写顺序代码与非阻塞 IO。 - Sans-IO 模式意在解决函数着色问题,简化测试,使库更易用于不同 IO 选择的情况。
- Rust 的异步与 Sans-IO 结合,可能需要处理 Pin 等问题,但有潜力提供更好的编程体验。
- 使用 Sans-IO 可将 IO 与主逻辑分离,更易单元测试主逻辑。
- 通过暴露状态,可使任何异步函数“纯净”,用户只需推动状态机到下一状态。
- Sans-IO 模式类似于端口/适配器架构风格,将 IO 从主功能中尽可能分离。
- 通过非阻塞 IO,可以同时等待套接字 IO 和时间,提高效率。
- Sans-IO 模式可减少函数着色问题,使库更易用于不同 IO 环境。
- 通过 Sans-IO 模式,可以更好地分离业务逻辑和执行模型,类似于 Free(r) monads 的思想。
Building a data compression utility in Haskell using Huffman codes #
https://lazamar.github.io/haskell-data-compression-with-huffman-codes/
这篇文章介绍了如何在 Haskell 中使用 Huffman 编码构建数据压缩实用程序。文章主要内容包括:

- Huffman 编码简介:介绍了 Huffman 编码的基本原理,即将字符映射到唯一的比特序列,使常见字符映射到较短的比特序列,稀有字符映射到较长的比特序列,从而实现压缩。
- 构建 Huffman 树:通过将字符按出现频率构建 Huffman 树,使频率较高的字符位于树的较浅位置,从而获得较短的编码。
- 编码和解码:展示了如何编写 Huffman 编码器和解码器,以及如何将文本编码为比特流并解码回原始文本。
- 处理二进制文件:介绍了如何处理二进制数据,将字节映射到 Huffman 编码,实现对二进制文件的压缩和解压缩。
- 序列化和反序列化:讨论了如何将频率映射和编码内容序列化为字节流,并如何从字节流中反序列化出频率映射和比特流。
- 应用到实际文件:展示了如何将这些功能应用到实际文件的压缩和解压缩过程中,以及如何通过命令行界面使用这些功能。
- 性能优化和改进:提出了一些可能的性能优化和改进方向,如多线程处理、单遍编码、规范化 Huffman 编码等。
总体而言,这篇文章详细介绍了如何使用 Huffman 编码在 Haskell 中构建数据压缩实用程序,并提供了实际应用的示例和性能优化的思路。
HN 热度 180 points | 评论 74 comments | 作者:lazamar | 19 hours ago #
https://news.ycombinator.com/item?id=40872332
- 数组式、原地算法减少了树分配和指针追踪的需求,更适合压缩时有大量数据且需要快速运行的情况。
- 有人提到 JPEG 标准 ITU T.81(1992)中有关数组式哈夫曼的算法,显示这种知识在 80 年代可能已经相对常见。
- 独特可译码不一定是前缀码,可以是前缀码的逆序。还提到了通过组合前缀码和后缀码来实现独特可译码。
- 有人提到 LZ 压缩更好,因为它可以轻松找到重复,而且解压速度非常快。
- Haskell 的性能可以与系统语言竞争,但其杀手功能在于抽象的便利,可以通过 FFI 调用无 GC 的语言进行优化。
- Haskell 的性能一般比 C 程序慢 2 到 5 倍,但内存占用可能是 C 的 2 到 10 倍。对于性能敏感但不是关键的程序,Haskell 是一个不错的选择。
- Haskell 在计算方面表现出色,更注重计算而非数据移动,这种思维方式非常优雅。