- 1次围观
2024-06-08 Hacker News Top Stories #
- Ice 是一款适用于 macOS 的开源菜单栏管理器。
- 用户 Wetterschneider 建议专业人士取消 Adobe。
- 微软将在安全反弹后默认关闭 Recall。
- 本文介绍了使用新方法分解 GPT-4 的内部表示。
- 文章介绍了 GPT-4o 处理图像的信息。
- 这篇博文讨论了谷歌在软件工程领域中人工智能的进展和未来发展方向。
- 这篇论文提出了一种新的自回归模型。
- 这个网站提供了三种方式来体验"Badness 0"项目。
- 用户 @Wojtek0586 提到了 HP Probook 455 G7 的 BIOS 升级问题。
- “CPU Energy Meter”是用于测量英特尔 CPU 能耗的工具。
Ice – open source menu bar manager for macOS #
https://github.com/jordanbaird/Ice
这个 GitHub 地址是关于名为"Ice"的强大 macOS 菜单栏管理工具。Ice 的主要功能是隐藏和显示菜单栏项目,旨在提供广泛的附加功能,使其成为最多功能的菜单栏工具之一。
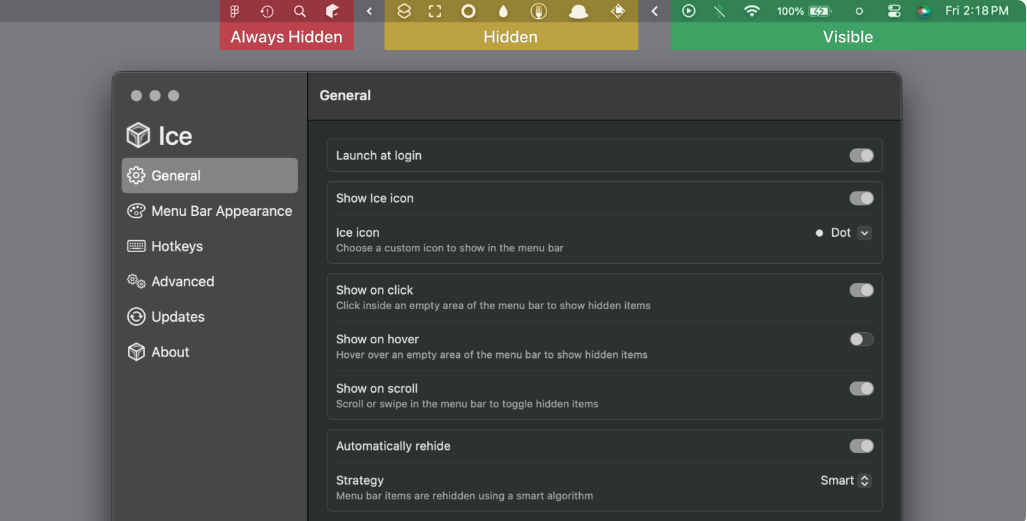
一些关键特性和路线图包括:
- 菜单栏项目管理:隐藏、显示菜单栏项目、“始终隐藏"菜单栏部分、悬停在菜单栏上时显示隐藏项目、点击菜单栏空白区域显示隐藏项目、滚动或在菜单栏中滑动显示隐藏项目、自动重新隐藏、当应用菜单与显示的菜单栏项目重叠时隐藏应用菜单等。
- 菜单栏外观:菜单栏色调(纯色和渐变)、菜单栏阴影、菜单栏边框、自定义菜单栏形状(圆角和/或分割)等。
- 快捷键:切换单个菜单栏部分、切换应用程序菜单、显示/隐藏部分分隔符图标、临时显示单个菜单栏项目、启用/禁用自动重新隐藏等。
- 其他功能:登录时启动、自动更新、菜单栏小部件等。
Ice 目前正在积极开发中,一些功能尚未实现。你可以从最新版本中下载 Ice,并查看下面的路线图以了解即将推出的功能。Ice 提供手动安装和 Homebrew 安装方式。该项目采用 MIT 许可证。
Ice 的名字来源于其让你的菜单栏像冰一样,使菜单栏项目可以滑动消失的特性。该项目专为 macOS 设计,使用 Swift 语言开发。
HN 评论 169 comments | 作者:saikatsg | 19 hours ago #
https://news.ycombinator.com/item?id=40605532
- Ice 取代 Bartender,虽然功能不及,但希望 Ice 继续改进;
- 旧 Bartender 作者信任,新所有者引发信任问题;
- 卖家隐瞒售卖细节引发争议;
- 个人对 Bartender 卖出感到失望,转向 Ice 或其他工具;
- Bartender 需要屏幕录制权限,引发隐私担忧;
- 用户对 Bartender 出售感到失望,寻找替代方案;
- Ice 功能不完善,但速度快,适合简单需求;
- 用户对 macOS 窗口管理和用户体验提出质疑。
Cancel Adobe if you are a creative under NDA with your clients #
https://twitter.com/Stretchedwiener/status/1798153619285708909
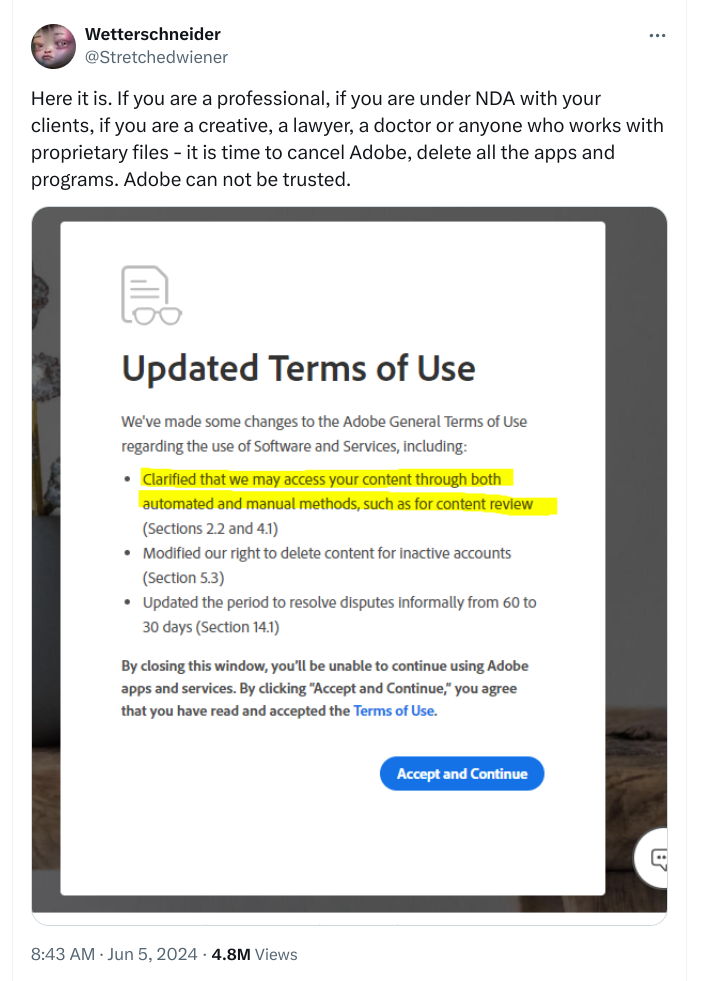
这条推特内容来自用户 Wetterschneider,内容是关于 Adobe 软件的。他建议如果你是专业人士、与客户签有保密协议、是创意工作者、律师、医生或者与专有文件打交道的人,现在是时候取消 Adobe,删除所有应用程序了。他认为 Adobe 不可信任。这条推文发布于 2024 年 6 月 5 日凌晨 12:43。
HN 评论 330 comments | 作者:wanderingmind | 13 hours ago #
https://news.ycombinator.com/item?id=40607442
- Adobe 取消费用绕过方法:更改当前计划,然后取消新计划,有效规避取消费用。
- Adobe 类似 Comcast,使用其他工具存在安全问题,老版本软件不再适用,软件公司价格应下降。
- 酒店预订取消费用规避方法:改变预订时间,然后取消。
- Adobe 回应称不会滥用权限,但对于 NDA 项目不够可靠。
- Instagram 改变 TOS 后称“相信我们”,Adobe 类似做法不受欢迎。
- Adobe 声称不滥用权限,但用户仍需谨慎。
- Adobe 访问用户内容声明引发争议,可能影响用户与客户协议。
- Adobe 用户内容许可声明引发担忧,可能导致滥用用户内容。
- Adobe 用户内容许可声明可能用于 AI 训练,引发隐私担忧。
Microsoft will switch off Recall by default after security backlash #
https://www.wired.com/story/microsoft-recall-off-default-security-concerns/
这篇文章讲述了微软在经历了持续的批评和曝光安全漏洞之后,大幅缩减了其 AI 功能“Recall”的规模,并增加了新的隐私功能。微软原本将其新的 Windows 功能命名为 Recall,意图是让这个词指代设备上一种完美的、由 AI 支持的记忆。然而,如今,“Recall”这个词的另一个意义——公司承认产品存在严重危险或缺陷,不得不从市场上撤回——似乎更为贴切。

微软宣布,他们将对 Recall 功能的推出进行多项重大改变,将其变为 Copilot+ 兼容版本 Windows 中的一个选择性功能,之前默认开启的 Recall 功能将变为选择性开启,并引入新的安全措施,旨在更好地加密数据并要求身份验证才能访问 Recall 存储的数据。
这些改变是在安全和隐私社区不断批评的背景下出台的,他们认为 Recall——这个会每五秒默默存储用户活动截图以供 AI 分析的功能——是给黑客的一份礼物:本质上是预装的间谍软件,内置在新的 Windows 电脑中。在 Recall 的预览版本中,截图数据,包括用户的每个银行登录、密码和访问的色情网站,将默认在用户的设备上无限期地收集。虽然这些高度敏感的数据存储在用户的设备上而不上传到云端,但网络安全专家警告称,只要黑客在用户的 Recall 启用设备上获得临时立足点,他们就可以长期查看受害者的数字生活。
除了将 Recall 变为选择性功能外,微软的 Davuluri 还写道,公司将进行改进以更好地保护 Recall 收集的数据,并更严格地监管谁可以启用它,要求用户通过其 Microsoft Hello 身份验证功能证明身份,每次他们启用 Recall 或访问其数据时都需要进行身份验证。Davuluri 表示,Recall 的数据将在用户进行身份验证之前保持加密状态。
尽管这些都是“巨大的改进”,但另一位前 NSA 黑客、现任网络安全咨询公司 Hunter Strategy 的 VP R&D Jake Williams 仍然认为 Recall 存在严重风险,即使是在最新的形式下。许多用户会打开 Recall,部分原因是微软对该功能进行了高调宣传。当他们这样做时,他们仍将面临许多未解决的隐私问题,比如家庭暴力者通常要求伴侣交出他们的 PIN 码,或者传票或诉讼迫使他们交出他们的历史数据。
对于微软来说,Recall 的回退发生在一系列令人尴尬的网络安全事件和数据泄露中,包括泄露了其客户数据的数千兆字节以及一系列微软安全失误导致的政府电子邮件账户遭到惊人的入侵,这些问题已经变得如此严重,以至于成为其与美国政府关系独特密切的一个症结点。
这些丑闻已经升级到微软的 Nadella 上个月刚刚发布备忘录,宣布微软将把安全作为任何业务决策的首要任务。在某些情况下,这意味着将安全置于其他事项之上,比如发布新功能或为传统系统提供持续支持。
总的来看,微软对 Recall 的推出——即使在今天的公告之后——显示出了相反的做法,似乎更符合微软一贯的商业惯例:宣布一个功能,因其明显的安全失败而受到严厉批评,然后迟迟才开始控制损害。
HN 评论 393 comments | 作者:georgehill | 7 hours ago #
https://news.ycombinator.com/item?id=40610435
- 当 Recall 被启用时,应该有一个覆盖层表明它处于活动状态,以便所有用户都知道。至少应该像旧的 Windows 激活覆盖层一样明显。
- 每个令人毛骨悚然的室友、坏伴侣、坏朋友等都会利用这一点做坏事。
- 如果屏幕录制默认打开,你的磁盘空间会很快用完。
- Chrome/Safari/Edge 浏览历史存储在未加密的 SQLite 数据库中,跟踪过去 90 天的活动。
- 很多人认为隐私和安全方面考虑不够。特别是如何忽略和绕过它。
- Microsoft 需要确保这些功能是安全的,而不是像 Xbox One 始终在线的 Kinect 要求一样。
- Recall 是一个强大的键盘记录器,可以搜索而无需技术知识。
- 如果这是一个真正的关注点,Recall 会是一个很好的名字,用于掩盖任何产品召回的搜索。
- 他们应该注意并召回 Recall。
- 如果他们真的相信这是人们想要的东西,他们应该把它做成一个真正的产品,而不是免费提供。
- 让市场决定,这就是这些资本家声称喜欢的东西,对吧?
Extracting concepts from GPT-4 #
https://openai.com/index/extracting-concepts-from-gpt-4/
本文介绍了使用新的可扩展方法来将 GPT-4 的内部表示分解为 1600 万个可解释的模式。目前我们并不了解如何理解语言模型内部的神经活动。作者分享了改进的方法,用于找到大量的 “特征”—— 希望这些活动模式是人类可以理解的。这些方法比现有工作更具规模化,作者使用这些方法在 GPT-4 中找到了 1600 万个特征。作者分享了一篇论文、代码和特征可视化给研究社区,以促进进一步探索。
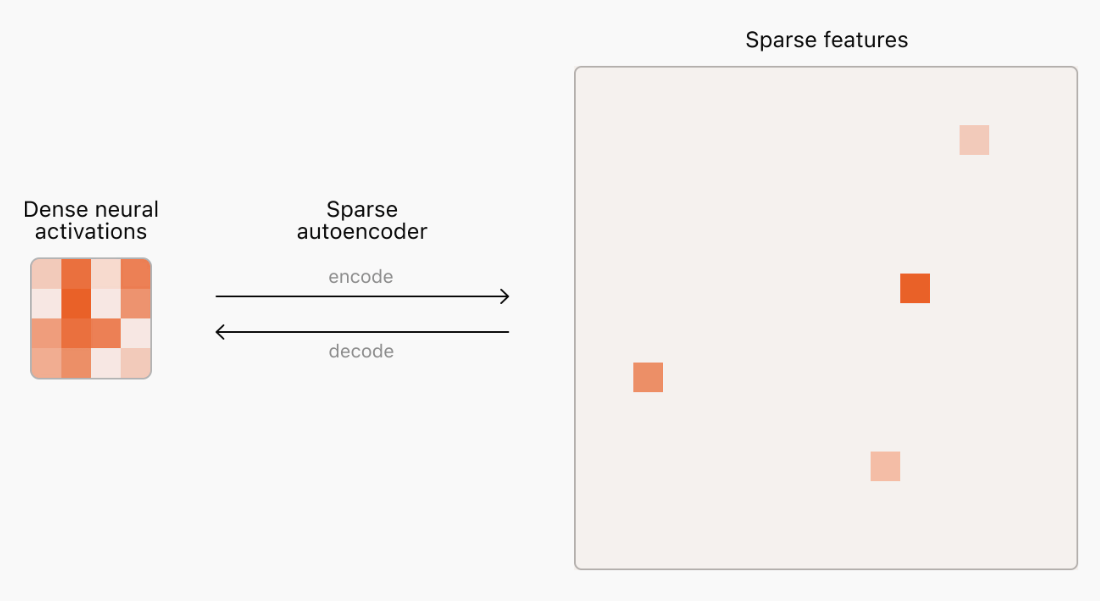
与大多数人类创造物不同,我们并不真正了解神经网络的内部运作。为了理解和解释神经网络,我们首先需要找到神经计算的有用构建模块。然而,训练稀疏自动编码器仍然存在严重挑战。大型语言模型代表着大量的概念,我们的自动编码器可能需要相应地庞大,以接近对前沿模型中的概念的完整覆盖。我们开发了新的技术,允许我们在前沿人工智能模型上扩展稀疏自动编码器到数千万个特征。我们的研究显示出平滑和可预测的扩展性,与之前的技术相比获得更好的规模回报。
我们使用这种方法在 GPT-2 small 和 GPT-4 的激活上训练了各种自动编码器,包括在 GPT-4 上的 1600 万特征自动编码器。为了检查特征的可解释性,我们通过显示激活该特征的文档来可视化给定的特征。一些我们找到的可解释特征包括:大多数人都不是这样。我们都有美好的日子,我们认为那是完美的片段,但我们也可以有真正糟糕的日子,我可以向你保证你并不孤单。
我们对可解释性感到兴奋,希望最终能够通过提供新的推理方式来增加我们对强大 AI 模型的信任。今天,我们分享了一篇详细介绍我们实验和方法的论文,希望这将使研究人员更容易地训练大规模的自动编码器。我们发布了一整套适用于 GPT-2 small 的自动编码器,以及用于使用它们的代码和特征可视化工具,以了解 GPT-2 和 GPT-4 的特征可能对应的内容。
HN 评论 139 comments | 作者:davidbarker | 1 day ago #
https://news.ycombinator.com/item?id=40599749
- 评论中提到 GPT-4 的特征并不总是与价格上涨有关,引发了一些误解。
- 评论中指出大多数示例并没有绿色突出显示的计数,这是为了展示这个神经元的特定性。
- 评论中提到高亮部分在可视化中更易于识别,显示了许多顶级激活并非显示增加。
- 评论中提到这项工作是在 Anthropic 的研究基础上进行的,但具有较少可解释和有趣的特征。
- 评论中指出 GPT-4 是一个更强大的模型,这使得训练具有相同质量特征的自动编码器更加困难。
How Does GPT-4o Encode Images? #
https://www.oranlooney.com/post/gpt-cnn/
本文介绍了关于 GPT-4o 如何处理图像的信息。首先指出,GPT-4o 在高分辨率模式下处理每个 512x512 瓦片需要消耗 170 个令牌。根据每个字大约需要 0.75 个令牌的计算,这意味着一幅图片价值约为 227 个字,与传统说法相差不远。

文章讨论了为什么选择 170 这个数字,提出了图像成本为什么转化为令牌数量的疑问。作者认为,可能图像瓦片实际上被表示为 170 个连续的嵌入向量。在探讨了嵌入的概念后,引入了转换文本和图像到嵌入向量的模型 CLIP。作者指出,GPT-4o 可能采用了一种不同于 CLIP 的策略来表示图像。
接着,文章猜测了 GPT-4o 内部用于表示嵌入向量的维度数量,并提出可能的数字。通过讨论嵌入图像的两种策略:基于原始像素和基于卷积神经网络(CNN),作者指出 CNN 在处理图像数据时具有优势,并对 CNN 的基本结构进行了介绍。
作者尝试推断 GPT-4o 可能使用的图像嵌入 CNN 的结构,并通过建议的 CNN 架构连接了已知的输入图像尺寸与假设的输出形状。通过一项实验验证,作者展示了 GPT-4o 是否真的看到了一个 13x13 的嵌入向量网格,并讨论了实验结果。
总体而言,本文详细解释了 GPT-4o 如何处理图像数据,通过分析嵌入向量的概念、CNN 结构以及实验验证结果,提供了对 GPT-4o 内部处理图像的深入理解。
HN 评论 100 comments | 作者:olooney | 11 hours ago #
https://news.ycombinator.com/item?id=40608269
- 需要一个现代的开源替代品取代 tesseract,使用当前的 SoTA ML 技术,以解决 OCR 问题。
- PaddleOCR 是一个不错的自托管 OCR,速度快,准确性高,包括中文。
- PaddleOCR 在新任务上的准确性很高,PaddleLayout 模型在推理速度和输出质量方面领先。
- LLM 的优势在于不需要制作许多专门的模型和管道,可以解决农民邻居愿意支付 500 美元的问题。
- Kosmos 可能是一个有趣且有趣的工具,但尚未进行详细测试。
- 苹果的 OCR API 在扫描文档和复制/翻译图像中的文本方面效果非常好。
- 对于手写识别,缺乏一个良好的开源模型。
- GPT-4o 可能使用 VQVAE 将图像转换为令牌嵌入,VQGAN 可能将 512x512 图像输出为 13x13 令牌。
- OpenAI 可能使用视觉变换器作为 GPT-4o 的工作方式。
- GPT-4o 可能具有音频令牌的词汇表,可能使用 RVQ-VAE 模型。
- 输入嵌入可能来自字典查找表,但不一定需要是文本令牌。
- 视觉变换器可能是 GPT-4o 的默认猜测,但文章中从未提到。
- GPT-4o 可能使用不同的视觉编码器将图像切片投影到文本标记器的分布空间。
- OpenAI 可能有一个单独的 OCR 模型,但更酷的是 LLM 可以从文本中理解语言。
- ChatGPT-4o 如何路由信息尚不清楚,图像中的文本是否被重新提交为文本查询,或者模型权重本身是否将文本图像转换为文本令牌。
AI in software engineering at Google: Progress and the path ahead #
https://research.google/blog/ai-in-software-engineering-at-google-progress-and-the-path-ahead/
这篇博文讨论了谷歌在软件工程领域中人工智能的进展和未来发展方向。自 2019 年以来,人工智能技术在软件工程中的应用取得了长足进步,尤其是在代码编写方面。谷歌内部工具中的机器学习技术已经被广泛应用,例如在代码自动补全方面。
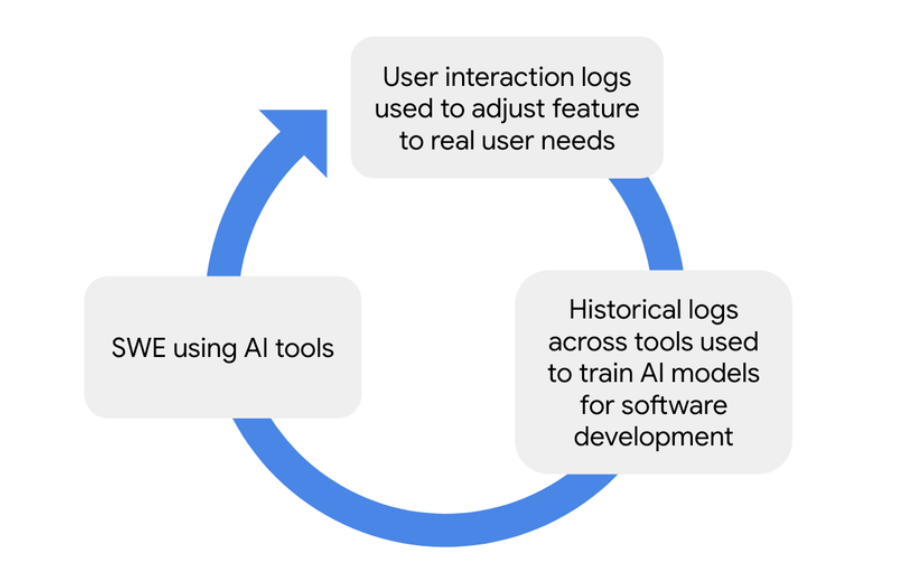
博文介绍了谷歌内部软件开发工具的持续转型中最新的 AI 增强功能,并讨论了未来 5 年预计会出现的进一步变化。团队负责谷歌工程师花费大部分时间的软件开发环境,包括内部循环(例如 IDE、代码审查、代码搜索)和外部循环表面(例如错误管理、规划)。改进这些界面可以直接影响开发人员的生产力和满意度。挑战在于 AI 技术发展迅速,很难预测首先探索哪些想法。
部署想法到产品时,我们遵循三项指导原则:根据技术可行性和影响力优先考虑,快速学习以改进用户体验和模型质量,以及衡量有效性。通过将大型语言模型应用于软件开发,特别是在代码完成工具中,谷歌取得了显著的进展。他们不断改进 AI 功能,如解决代码审查意见和自动调整粘贴代码等。通过高质量的数据和用户反馈,他们不断优化模型,以提高开发人员的生产力和满意度。
未来,谷歌计划进一步发展基于最新基础模型的应用,以提供更广泛的软件工程活动支持,如测试、代码理解和代码维护。他们鼓励业界共同努力,提出更多的基准测试,以促进实际工程任务的发展。
HN 评论 197 comments | 作者:skilled | 1 day ago #
https://news.ycombinator.com/item?id=40601116
- 当 AI 被正确使用时,它主要做两件事情:1)进行非争议性修复,节省时间并减轻开发者的认知负担,最好的例子是代码自动补全工作良好时;2)通过提出的建议使您更聪明、更有知识,即使您可能会丢弃这些建议,但您仍会学到一些新知识,让助手为您进行头脑风暴使您能以不同的思维方式进行想法筛选,这既有趣又有益,有用且令人放松。
- 文章中提出了一个有趣的观点,即 AI 工具在用户必须记得触发功能时“无法扩展”。
- AI 如何在不需要用户“触发”的情况下有用地建议设计级别和概念性想法?在 IDE 中,我不确定。自动评论解决的示例很有趣且“自动”,但可能不太可能是特别高级的性质。这也发生在代码审查的“外部流程”中。对我来说,最有趣的是“内部流程”,因为那时真正的创造力正在发生。
- Clippy 在错误的时间上走了正确的道路,问题不在于监视您的工作并提供帮助的助手的概念,问题在于它可以检测到一个字母,提供帮助,但它给出的帮助只是一堆浅薄的格式建议,没有与实际工作相关的上下文。一个真正的助手可以在您到达目的地之前预测您需要什么,并且在您到达之前以 95% 的成功率创建它,这样的助手不会感觉像 Clippy。
- Clippy 来自微软?这是技术人员真正失去了视角的地方…您看,这不仅仅是一台计算机、一家计算机公司和一个用户..现实生活包括具有社会契约的社会系统,以及用户的日志、记录和自治与经济关系的“主人”之间的关系。微软已经明确表示,监视用户并限制自主权对商业角度至关重要,甚至比实际行动更有价值,同时,整个行业产品线的设计旨在使个人技能变得微不足道,并使工作表现更像可替代的零件工作。
- 最后,人们或多或少意识到这些其他工作中的动态。然而,人们是人类,会对其他社会暗示做出反应。某些东西之所以如此受欢迎,是因为它新颖、可爱或特别“酷”,这确实会影响采纳和实施的程度。Clippy 是对苹果用创新的 GUI 元素获得“酷”评价的直接市场回应。
σ-GPTs: A new approach to autoregressive models #
https://arxiv.org/abs/2404.09562
这篇论文的标题是《σ-GPTs: 一种新的自回归模型》,作者是 Arnaud Pannatier、Evann Courdier 和 François Fleuret。传统的自回归模型(如 GPT 系列)通常使用固定的顺序(通常是从左到右)生成序列,但这并非必须。本文挑战了这一假设,通过简单地为输出添加位置编码,可以实现每个样本动态调节顺序,从而带来关键的优势特性。
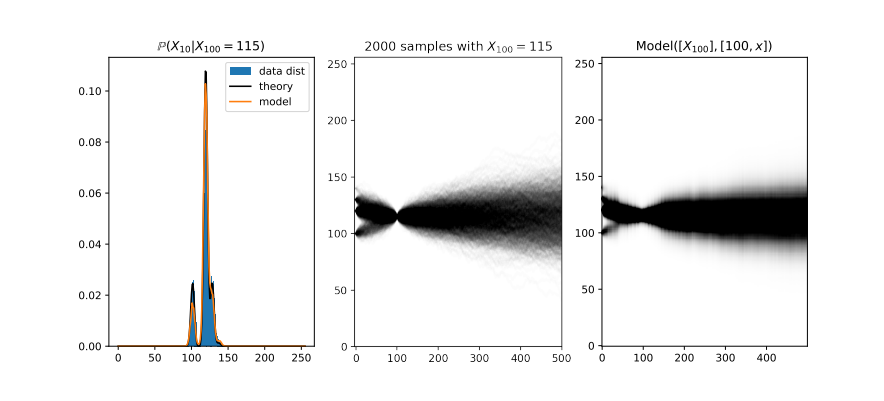
这种方法允许对任意子集的标记进行采样和条件化,并且还允许根据拒绝策略动态一次性采样多个标记,从而导致模型评估数量的次线性增长。作者在各个领域评估了他们的方法,包括语言建模、路径解决和飞机垂直速率预测,在生成过程中减少了所需步骤的数量一个数量级。
论文涉及的主题包括机器学习和人工智能。这项研究提出了一种新颖的方法,可以改变自回归模型生成序列的顺序,从而在多个领域中取得了显著的效果。
HN 评论 59 comments | 作者:mehulashah | 11 hours ago #
https://news.ycombinator.com/item?id=40608413
- 作者通过随机排列输入标记并为每个标记添加两个位置编码,使模型能够并行一次性填充缺失标记,计算序列中每个缺失标记的条件概率密度,并提出了一种用于生成填充标记的拒绝抽样方法;
- 该问题表述已存在一段时间,但与 PixelCNN 等相关的不同之处在于位置嵌入的概念;
- 有人不理解并行预测的工作原理,但模型经过训练,可以预测任何位置的标记;
- 模型的采样方法拒绝不可能的组合,但完整句子是否合理仍有疑问;
- 与常规 GPT LLMs 相比,这种保证并不存在,但模型输出的概率分布会自动根据前一个标记进行调整;
- 温度参数在采样时很重要,可以影响采样结果的分布形状;
- 该方法可能适用于计算机代码生成,但速度可能是一个问题;
- 该算法是否能为现有大型文本/图像模型带来明显实际应用,以及拒绝抽样是否能从联合概率分布中获得统计正确样本,仍有待探讨;
- 该方法可能是将视觉 Transformer 的经验应用于语言 Transformer 的一种尝试。
Tom 7: Badness 0 (Three ways) #
这个网站是关于一个名为"Badness 0"的项目,提供了三种方式来体验这个项目。

第一和第二种方式是阅读 Knuth 的版本和 Epsom 的版本,它们出现在 SIGBOVIK 2024 的会议记录中。需要注意的是,由于一个名为"BUG"的问题,这些版本似乎只能在 Chrome 浏览器中正确显示。作者表示正在努力修复这个问题,而 SIGBOVIK 会议记录中的版本可能会正常显示。
第三种方式(推荐)是坐下来沉浸在 4k、60Hz 的闪烁灯光中,这是"Badness 0"的最新版本。如果想直接体验"BUG",第四种方式是立即查看源代码。作者表示会在休息后添加一些关于编译和使用的说明。源代码可在 GPL(COPYING)或 GJPL(JCOPYING)下获得。
此外,作者的 YouTube 频道上还有一些视频。欢迎在作者的博客或 Mastodon 上留言。更多信息请访问[tom7.org]。
HN 评论 39 comments | 作者:cubefox | 11 hours ago #
https://news.ycombinator.com/item?id=40608332
- Tom7 的视频让人感觉像是硕士论文般的视频论文,每个项目都是杰作;
- Tom7 的视频让人感觉自己置身于某种比自己更聪明的秘密俱乐部中;
- 一位 54 岁的计算机科学本科生表示,虽然不懂 Curry-Howard(或 Hurry-Coward),但这篇论文让他感到愉悦;
- 有人认为在软件中加入半吊子彩蛋成就系统是个好主意,可以增加软件的趣味性;
- 有人担心在处理大数据时收到“成就解锁”消息可能会导致调试困难;
- 有人分享 Tom7 的视频中他用 NES 玩 SNES 游戏的视频链接;
- 有人推荐观看 Tom7 的视频《Harder Drive: Hard drives we didn’t want or need》;
- 有人表示 Tom7 的视频无法用简短概括,是关于两篇论文的主要思想;
- 有人提到 Tom7 的视频结尾有一个很棒的笑话;
- 有人指出视频中的一些错误可能是故意为之,比如网站 URL 中的反斜杠;
- 有人分享了一篇 PDF,表示排版非常糟糕;
- 有人讨论了 Wordle 游戏的“Hard Mode”存在的问题。
HP bricks customers laptops with faulty automatic BIOS upgrade #
在这个 HP Support Community 的页面上,用户 @Wojtek0586 提到了 HP Probook 455 G7 的 BIOS 升级问题。
他指出 HP 尚未就此问题发布官方声明,这些笔记本即将进入三年保修期的最后几天,对于已过保修期的设备,官方更新导致了设备故障,谁来承担维修费用?这一事件似乎影响范围很大,涉及全球。
用户表示难以置信只有他们在这些帖子中遇到了 455 G7 设备变砖的问题,这一事件可能影响了数百万台设备。用户分享了自己的经历,当他的设备因糟糕的 BIOS 更新而变砖时,他开始怀疑自己的 IT 资产管理技能,但后来得知 HP 已从服务器中删除了 BIOS 更新,他才意识到这并非个例。
用户还提到了一些人建议使用 GPO 来阻止 BIOS 更新,但他认为这些建议并不可靠。最后,用户表示下一步计划是关闭所有机器上的“Native OS Firmware Update Service”以永久禁用 UEFI Capsule BIOS 更新。
HN 评论 116 comments | 作者:jackpot433 | 1 day ago #
https://news.ycombinator.com/item?id=40601711
- HP 产品质量一直存在问题,曾有高端产品缺陷,售后处理不佳,产品一直不尽人意。
- HP 有好有坏,有些产品好有些糟糕,例如 Z 系列工作站性能好,但也有很多糟糕的产品。
- Dell 也曾类似,例如 XPS L702x 只有一个 DIMM 插槽,实际上宣传有两个,售后处理不佳。
- HP Spectra X360 在工作中表现良好。
- HP BIOS 更新方式存在风险,可能导致笔记本变砖。
- 应该有两个 BIOS,依次更新,但对于终端用户笔记本可能未解决。
- HP 应该提供更安全的 BIOS 更新方式,避免意外损坏。
- HP 可能存在 CFAA 问题,可能未经授权访问并损坏计算机。
- HP 消费类产品质量差,不值得信赖。
- HP 消费类产品与专业产品质量差距大。
- HP 分拆后,HPE 服务器质量好,HP 消费类产品不佳。
- HP 服务器质量好,例如 17 年前的 DL140 仍在工作。
- HP 服务器驱动和固件更新现在可能需要付费。
- HPE 和 HP Inc.是不同公司,服务器和 PC 产品质量差异明显。
CPU Energy Meter: A tool for measuring energy consumption of Intel CPUs #
https://github.com/sosy-lab/cpu-energy-meter
这个 GitHub 地址( https://github.com/sosy-lab/cpu-energy-meter)包含了一个名为“CPU Energy Meter”的工具,用于测量英特尔 CPU 的能耗。以下是该工具的详细信息:
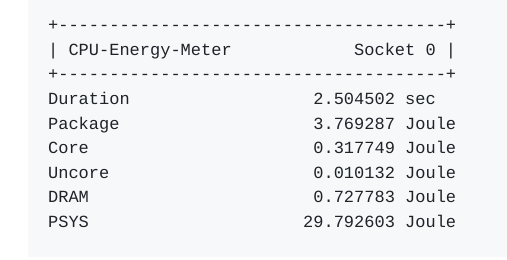
- CPU Energy Meter 是一个用于 Linux 的工具,允许以细微的时间粒度(几十毫秒)监视英特尔 CPU 的功耗。
- 支持以下功耗域的功耗监控:
- 每个包域(CPU 插槽)
- 每个核心域(包中的所有 CPU 核心)
- 每个 uncore 域(uncore 组件,例如客户端 CPU 上的集成图形)
- 每个内存节点(包内的本地内存,仅适用于服务器 CPU)
- 每个平台(平台上接收来自集成电源传递机制的电源的所有设备,例如处理器核心、SOC、内存、附加设备或外围设备)
- 该工具利用英特尔 CPU 的一个名为 RAPL(Running Average Power Limit)的特性,该特性在英特尔软件开发人员手册第 3B 卷第 14.9 章节中有文档。RAPL 可用于从 Sandy Bridge 一代以后的 CPU。
- 由于 CPU Energy Meter 使用最大可能的测量间隔(取决于硬件,介于几分钟到一小时之间),因此造成的开销可以忽略不计。
- CPU Energy Meter 是 Intel Power Gadget 的一个分支,由慕尼黑大学路德维希-马克西米利安大学(LMU Munich)的软件系统实验室(Software Systems Lab)开发,采用 BSD-3-Clause 许可证。
- 安装方式包括从 PPA 安装(适用于 Debian 或 Ubuntu),或者从 GitHub 下载.deb 包并使用 apt install ./cpu-energy-meter*.deb 安装。
- CPU Energy Meter 的依赖项包括 libcap(大多数 Linux 发行版中的 libcap 软件包)和带有 MSR 模块的 Linux 内核(默认情况下可用)。
- 该工具还提供了从源代码运行的选项,并提供了详细的安装和使用说明。
希望这个摘要能够帮助您了解有关 CPU Energy Meter 工具的详细信息!
HN 评论 54 comments | 作者:todsacerdoti | 22 hours ago #
https://news.ycombinator.com/item?id=40604596
- Intel CPU 的能耗值是准确的,使用校准过的电流传感器,而不是近似值。
- AMD 有类似的 uProf 工具,但一些功能仅限于 EPYC CPU。
- AMD Energy 传感器信息限制为 root,导致驱动被移除。
- CPU 利用率增加会导致功耗增加。
- 监控工具本身会消耗一定能量,例如 netdata 可能会使 CPU 功耗从 100mw 增加到 5W。