- 15 次围观
2024-06-01 Hacker News Top Stories #
- 南极洲网络受限,开发者应测试 Web 应用在 3G 网络下的表现。
- 日本推动公共资助研究成果免费阅读,提高研究信息可追溯性。
- Snowflake 数据泄露,黑客通过信息窃取者感染确认访问权限。
- 男子被要求隐藏船只,在围栏上画了船。
- ShadeMap 可计算全球阴影位置。
- IRS Direct File 计划将向所有州开放,为美国人节省时间和金钱。
- AWS S3 存在一些奇怪之处和注意事项。
- 《尤利西斯》是詹姆斯·乔伊斯的著名小说。
- 研究人员通过舍入数字让大型语言模型更便宜、快速且环保。
- 作者通过传真软件和创造性方法从 30 年前的笔记本电脑中复制文件。
Engineering for Slow Internet #
https://brr.fyi/posts/engineering-for-slow-internet
这篇名为“Engineering for Slow Internet”的文章讲述了作者在南极洲使用受限卫星网络时的工程经历。作者分享了在南极洲使用互联网的挑战,包括高延迟、低带宽、连接不稳定等问题。

作者在南极工作期间,只能通过美国南极计划提供的极其有限的卫星链路访问互联网。南极的网络连接是非常有限的,与美国郊区 4G 蜂窝网络相比,整个站点的带宽共享速度甚至更低。虽然最近在麦克默多和帕尔默地区有了重要的发展,南极站的情况仍然相当糟糕。
南极站的互联网连接仅在每天的几个小时内提供,由于卫星的限制,用户面临着很高的往返延迟,速度很慢,拥塞严重,连接不稳定。文章还提到了作者在南极使用网页和应用时遇到的问题,因为一些应用没有考虑到慢速和不稳定的链接,导致用户体验受到影响。
最后,作者列举了一些希望开发人员在设计应用程序时可以考虑的因素,以减轻慢速网络带来的问题。文章强调了即使南极是个特殊案例,但在全球范围内仍有许多使用较慢或不稳定网络的用户,他们也值得开发者的考虑。
HN 评论 295 comments | 作者:jader201 | 19 hours ago #
https://news.ycombinator.com/item?id=40531100
- 建议开发者可以回到 2005 年或者使用 Web 工具的限速功能来测试他们的 Web 应用在 3G 网络下的表现,以学习如何更灵活地构建。
- 提到了一些 Web 站点首页因为广告和预加载视频而有 250MB 的负载,这对于用户流量有限的人来说是一个问题。
- 有人表示在现代前端技术中,对于慢网络来说 React 是比较好的选择,同时也提到了一些优化手段。
- 有人认为在处理慢网络时,最轻量级的 JS 框架不是 React,而是根本不用 JS,但有人也指出在某些情况下这可能会导致更大的问题。
- 讨论了 SPA 和 “为慢网络设计” 的关系,指出大型捆绑包和增量渲染可能会导致页面在慢网络下表现不佳,提倡使用离线优先构建 SPA。
- 有人分享了在开发 SPA 时遇到的一些挑战,以及如何通过优化 HTTP 请求和减少依赖来改善性能。
- 讨论了 HTTP 请求的数量对页面加载时间的影响,以及如何优化 HTTP 请求来提高页面性能。
- 最后提到了一些 Web 浏览器可能会因为请求过多而导致性能问题,建议减少请求来避免这种情况。
Japan’s push to make all research open access #
https://www.nature.com/articles/d41586-024-01493-8
这篇文章介绍了日本政府推动所有公共资助的研究成果在机构知识库中免费阅读的计划。日本科学部将在六月向大学分配资金,以建立必要的基础设施,使研究论文在全国范围内免费阅读。该计划旨在提高研究信息的长期可追溯性,促进二次研究和合作。日本是亚洲首个在推动更多研究开放获取方面取得显著进展的国家之一,也是世界上首批制定全国性开放获取计划的国家之一。

日本教育文化体育科学技术省宣布,将投资约 100 亿日元(约合 6300 万美元)用于标准化机构知识库,以确保日本的研究开放获取机制。日本已有大约 800 所大学,其中超过 750 所已经拥有机构知识库。日本还推出了自己的国家预印本服务器 Jxiv,但使用仍然有限。日本的开放获取策略主要集中在“绿色开放获取”上,即作者在数字知识库中提供论文的作者接受但未最终确定的版本。
日本的研究开放获取计划受到赞扬,因为它将确保日本所有学术界产生的研究都有一个统一的记录。这一政策将使日本在这方面走在其他国家前面。文章还提到,日本计划加强支持大学知识库的同时,也在努力提高博士学位持有者的数量,以应对国际研究地位下降的挑战。
HN 评论 93 comments | 作者:sohkamyung | 20 hours ago #
https://news.ycombinator.com/item?id=40530670
- “OA 被认为是公共资金的浪费,OA 是一个从欧洲国家抽取公共资金的大计划,出版商竞争质量的研究输出的理念基本被消除,OA 是一个公共资金的大漏洞,OA 是一个更昂贵的骗局,OA 不是真正的开放获取”
- “审稿人被推动接受论文而不是拒绝,拒绝的论文不赚钱,审稿人压力难以察觉,OA 是一个自我实现的预言,OA 不是颠覆性的,OA 和传统出版一样资本主义邪恶”
- “日本的倡议集中在“绿色开放获取”,金色 OA 在大规模上不可行,大部分人将找到付费版本,OA 实现方式是自我实现的预言”
- “大部分最新 AI/ML 工作是真实的,但并非所有研究都是如此,大部分 STEM 领域似乎适用,社会科学可能滞后”
- “社会科学在预印本到数字档案方面滞后,社会科学比 STEM 领域滞后,社会科学对预印本数字档案的需求更大”
- “OA 是一个童话般的幻想,OA 是一个昂贵的骗局,OA 是一个自我实现的预言,OA 不是颠覆性,OA 是资本主义邪恶”
- “绿色 OA 是常规出版,但具有自我存档,绿色 OA 是一个有前途的途径,绿色 OA 是一个有前途的途径”
- “日本计划使所有公共资助的研究在机构知识库中可读,数据访问是重点,数据共享是挑战,数据管理流程是关键”
Snowflake breach: Hacker confirms access through infostealer infection #
https://www.hudsonrock.com/blog/snowflake-massive-breach-access-through-infostealer-infection
根据网站内容,Snowflake(云存储巨头)遭受了一次大规模数据泄露,黑客通过 Infostealer 感染获取访问权限。研究人员通过与这次云存储巨头 Snowflake 的大规模数据泄露背后的威胁行为者直接沟通,获得了对 Infostealer 感染的毁灭性影响的前所未有的洞察。

故事始于 5 月 26 日,在与声称已经黑客入侵了两家主要公司 Ticketmaster 和桑坦德银行的威胁行为者的 Telegram 对话中。这些公司的数据在俄语犯罪论坛 exploit[.]in 上公开出售。威胁行为者提供的数据库样本使 Hudson Rock 的研究人员相信数据是真实的。在与 Hudson Rock 的对话中,威胁行为者透露,故事远不止这两次数据泄露,还有其他一些主要公司遭受了类似命运,据称包括许多 Snowflake 的客户。进一步解释黑客的来源,威胁行为者补充说,所有这些数据泄露都源自单个供应商 Snowflake 的黑客入侵。
为了了解黑客是如何实施黑客入侵的,威胁行为者解释说,他们能够使用窃取的凭据登录 Snowflake 员工的 ServiceNow 帐户,从而绕过了位于 lift.snowflake.com 上的 OKTA。在渗透之后,威胁行为者声称他们能够生成会话令牌,从而使他们能够从公司中大量窃取数据。总的来说,一个凭据导致了潜在地数百家使用 Snowflake 存储数据的公司的数据泄露,威胁行为者本人暗示有 400 家公司受到影响。威胁行为者的目标,如大多数情况下一样,是勒索 Snowflake 以 2000 万美元的价格购买他们自己的数据。
然而,公司似乎没有回应。数据泄露的进一步证据包括威胁行为者与 Hudson Rock 的研究人员分享的一个 CSV 文件,显示了他们对 Snowflake 服务器的访问深度。这个文件记录了与 Snowflake 的欧洲服务器相关的超过 2000 个客户实例。通过 CSV 文件中的数据,Hudson Rock 的研究人员确定了一名 Snowflake 员工,该员工于 2023 年 10 月 5 日被 Lumma 类型的 Infostealer 感染。除了其他对 Snowflake 基础设施的敏感凭据,这名员工的登录详细信息(adelou)到一个特定服务器(https://sfseeurope-demo_adelou.snowflakecomputing.com)也遭到了泄露。当被问及用于实施黑客入侵的具体凭据时,威胁行为者向 Hudson Rock 的研究人员确认了确实使用了这些凭据,并与我们分享了一个共同的看法,即这次巨大的黑客入侵本可以很容易地被阻止。
目前尚不清楚哪些其他公司受到了黑客入侵的影响。我们预计这些信息将随着与受影响公司的谈判而慢慢披露。5 月 31 日,Snowflake 发布了一份声明,称他们正在调查一场影响“一些”客户的行业范围的基于身份的攻击。Hudson Rock 将继续跟进与这次黑客入侵相关的更新。Infostealer 感染作为一种网络犯罪趋势自 2018 年以来激增了惊人的 6000%,将其定位为威胁行为者用于渗透组织并执行网络攻击的主要初始攻击向量,包括勒索软件、数据泄露、账户接管和企业间谍活动。
HN 评论 133 comments | 作者:zbangrec | 8 hours ago #
https://news.ycombinator.com/item?id=40534868
- SE 的凭证被盗,可能导致客户数据泄露
- Snowflake 的安全实践导致客户需与员工共享广泛数据访问
- Snowflake 的漏洞可能导致客户数据泄露
- Snowflake 账户可能缺少 2FA 保护
- 客户数据存储在 Snowflake 的 AWS 账户上
- Snowflake 可能需要更好的安全控制
- Snowflake 员工可能需要访问客户数据
- Hudson Rock 的公开方式可能不专业
- Hudson Rock 可能过度自我吹嘘
- Hudson Rock 可能在曝光受害者时不恰当
- Hudson Rock 的文章可能缺乏一致性
- Hudson Rock 可能在推广中表现不佳
- Hudson Rock 可能未经独立验证
- Hudson Rock 可能不是可靠来源
A man ordered to hide his boat painted the boat on his fence #
https://news.artnet.com/art-world/fence-boat-painting-artist-hanif-panni-2487875
这篇文章讲述了加利福尼亚州西海滨小镇 Seaside 的一位居民 Etienne Constable 被要求建造围栏来掩盖他车道上的船只。他按要求建造了围栏,然后雇佣了邻居、艺术家 Hanif Panni 在围栏上绘制了一幅壁画,逼真地描绘了船只本身。

这种行为被形容为一种被动挑衅,也被称为恶意顺从,但无论如何,都被认为是滑稽可笑的。Constable 表示,他喜欢在必要时发表政治性、幽默性和创造性的言论。这个故事在新闻媒体中广为传播,在社交媒体上迅速走红。
Hanif Panni 是一位多才多艺的艺术家,他被邀请为其他居民绘制船只壁画。这一行为被认为是一种对规定的创造性回应,也展示了社区驱动的解决方案。

文章还介绍了 Hanif Panni 的艺术背景和作品如何融入艺术历史传统。整篇文章充满了幽默和创意,展示了艺术如何在日常生活中发挥作用。
HN 评论 369 comments | 作者:geox | 15 hours ago #
https://news.ycombinator.com/item?id=40531984
- 美国自由之地是能够携带枪支进入学校,但因为草太长被罚款。这类 HOA 故事总是很有趣。
- 自由结社的真正含义是自由加入任何我们想要的团体,但有时候加入会是一个错误。
- HOA 需要超越自由结社的能力,将未来任何地块的所有者绑定到 HOA。
- HOA 通常有明确的规则和改变执行这些规则的流程。
- HOA 可以是有用的,也可以是小气且由报复心态的白痴管理。
- 人们有自由犯错的自由,甚至是犯大错的自由。
- 真正的自由包括犯错误的自由,即使是大错误。
- HOA 的存在并非自由结社,而是私有化的故事。
- HOA 的问题在于缺乏移动自由和多样化的“HOA 风格”,因此没有选择不加入。
- 社区需要组织,但对于 HOA 这种私人组织,应该受到地方政府规则的约束。
Every mountain, building and tree shadow in the world simulated for any time #
ShadeMap 是一个全球的山地、建筑和树木阴影模拟系统,可以根据任何日期和时间计算阴影位置。它可以实时计算阴影位置并在地图上显示出来,也可以汇总一段时间内的影情况,从而计算出特定位置一天或一年内获得阳光或阴影的小时数。
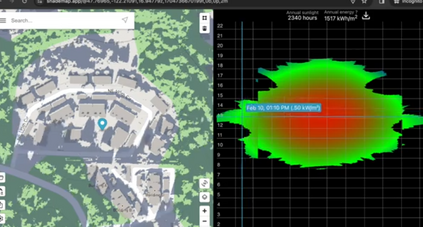
用户可以利用 ShadeMap 规划户外活动,如攀岩、滑雪和登山,也可以用于夏季户外婚礼等活动,以寻找遮荫地点。除此之外,ShadeMap 还可以用于太阳辐射图、房地产评估、光伏潜力评估、摄影、活动规划、生态学和农业研究等各种用途。用户可以在 ShadeMap 上查看特定位置接收到的直接阳光小时数,也可以查看该位置一整年内的直接阳光总量。
建筑数据来自 OpenStreetMap 等志愿者贡献的免费数据,也会购买 Mapbox 等服务提供商的数据,以获取更精确的建筑高度信息。用户可以使用绘图工具在地图上标注自己的房屋,并设置高度。通过购买高级数据,用户可以获得更精确的阴影模型数据,包括通过激光雷达和摄影测量获得的准确建筑布局、屋顶和树木高度信息。此外,用户还可以购买树木数据,以在地图上显示准确的树木阴影。
ShadeMap 还提供了显示太阳方向、日出和日落线的功能,用户可以调整日期和时间来查看这些线的方向。用户可以使用 ShadeMap 来规划自己的花园,也可以购买树木数据以查看树木阴影。
HN 评论 1 comments | 作者:wfme | 16 hours ago #
https://news.ycombinator.com/item?id=40531699
- 评论中有人认为这项技术对于城市规划和环境保护有巨大潜力
- 一些人担心这种技术可能被用于监视和侵犯隐私
- 也有人指出这种技术在军事和情报领域可能会有应用
- 有人认为这种技术对于电影和游戏行业也会有很大帮助
IRS Direct File to open to all 50 states and D.C. for 2025 tax season #
https://www.axios.com/2024/05/30/irs-taxes-direct-file-free-program
根据 Axios 的报道,财政部于周四宣布,IRS(美国国内税收局)的“直接申报”计划,即免费在线报税计划,将在 2025 年税季永久开放给所有 50 个州和华盛顿特区参与。这一举措对于不必花钱报税的美国人来说将是一个福音,同时可能对私人报税服务(如 TurboTax)造成巨大打击。

本月早些时候,财政部宣布,在 12 个州有超过 14 万人参与了“直接申报”试点计划,申报退税金额超过 9000 万美元。在过去的税季中,这一试点计划超过了其 10 万人的目标。财政部长珍妮特·耶伦在一份声明中表示:“拜登总统致力于为美国人节省时间和金钱,确保家庭获得他们应得的税收优惠。为所有希望选择直接向 IRS 报税的美国人提供免费工具对实现这些目标至关重要。”该试点计划针对拥有简单税务申报(基于 W-2 表格)的人群。
耶伦在今天的讲话中表示,未来几年他们将扩大“直接申报”以支持更多情况。一些民主党议员支持“直接申报”计划,并表示希望进一步扩大。民主党众议员布拉德·谢尔曼(加州)在四月告诉 Axios,他希望“远远超出直接申报”,呼吁推出“自动填表”。“为什么你要在政府已经掌握所有信息的情况下填写你的申报表呢?他们在你之前就知道你的 W-2 表格上有什么。他们知道你的 1099 表格上有什么… 你知道人们会犯多少错误吗?”另一位支持扩大的民主党参议员伊丽莎白·沃伦(马萨诸塞州)在一份声明中表示:“我敦促每个州和哥伦比亚特区采纳‘直接申报’计划。”“今年的‘直接申报’试点证明了政府完全有能力提供一个免费的公共电子申报服务,为纳税人节省时间、金钱和麻烦,”自由公平报税联盟表示。
该联盟是由 125 个国家和州组织组成,他们推动了免费申报。“IRS 不仅做出了继续该计划的正确决定,而且应该扩大规模,以覆盖更广泛的美国人。”税务保护联盟发言人卡拉·祖普库斯在一份声明中表示,扩大该计划将“极大地增加 IRS 的权力和范围”,“将产生灾难性后果”。私人税务服务“有充分的动机去寻找能为他们带来最佳回报的减免”,祖普库斯补充说,IRS 希望“尽可能多地从纳税人那里收取”。她表示:“这是在寻找问题的解决方案… 这里唯一的结果将是更多的延迟和辛勤工作的美国人口袋里的钱更少。”
HN 评论 239 comments | 作者:kjhughes | 6 hours ago #
https://news.ycombinator.com/item?id=40536400
- 该项目成功将产品推向小范围税务情况和州份,以便在 9 个月内实现可行性,成功提交了 15 万份税务申报。
- 有评论指出加州大多数软件工程师的收入超过 20 万美元,可能无法使用直接提交,需要重复工作两次。
- 有人认为超过 20 万美元的收入限制是为了保持试点年份的范围,避免支持 Form 8959 等复杂情况。
- 有评论提到,年收入超过 20 万美元的人可能会使用 CPA,而不是直接提交,以优化税收负担。
- 有人认为直接提交不适合大多数软件工程师这类复杂税务情况,但希望未来州份能与其整合税务系统。
Things you wish you didn’t need to know about S3 #
https://blog.plerion.com/things-you-wish-you-didnt-need-to-know-about-s3/
这篇博文标题为《Things you wish you didn’t need to know about S3》,作者是 Daniel Grzelak。文章讨论了关于 AWS S3 的一些奇怪之处和注意事项。
文章指出 S3 桶是 S3 API 的一部分,其中一些 API 请求需要发送到通用的 S3 端点,而大多数请求必须发送到目标桶的 URL。S3 桶可以是公开的也可以是私有的,这可能导致一些 API 操作的混淆。文章还提到了关于未完成的分段上传的问题,以及如何使桶公开访问的方法,例如通过 Amazon CloudFront 分发和 AWS Cognito 身份池。
此外,文章还讨论了一些安全性问题,如使用 UTF-8 字符在对象键名中可能导致的问题,以及如何通过 ListBucket 操作来确定特定账户 ID 是否是给定可访问桶的所有者。文章还提到了一些有趣的细节,比如存储类是上传者的选择,键名是区分大小写的等。
HN 评论 178 comments | 作者:miles | 18 hours ago #
https://news.ycombinator.com/item?id=40531301
- 一些人认为文件系统应该区分大小写,认为这是正确的做法,而且对于文件名的大小写敏感性并不会导致普遍问题。
- 另一些人认为大小写敏感性有助于逻辑分组和避免错误,尤其在终端环境中使用时更为实用。
- 也有人指出大小写对于文件系统来说并不重要,认为文件系统应该保持大小写不敏感,以避免复杂性和错误。
- 有人提到在不同语言环境下,大小写敏感性可能会带来更多问题,因此应该考虑更多语言的需求。
- 还有人讨论了 S3 中的路径模拟和未完成的多部分上传可能导致的问题,以及 AWS 服务的复杂性和费用问题。
Standard Ebooks' 1,000th title: Ulysses #
https://standardebooks.org/ebooks/james-joyce/ulysses
《尤利西斯》是詹姆斯·乔伊斯的著名小说,也是英语文学中备受推崇的作品之一。小说记录了 1904 年 6 月 16 日星期四在都柏林市发生的事件。故事首先介绍了史蒂芬·德达勒斯,他是乔伊斯之前小说《画家的青年时代》中的主人公。史蒂芬现在住在一个租来的马泰洛塔楼,并在一所学校工作,完成了他的学士学位和在巴黎尝试进修的一段时间。然后故事转向了本书的主人公利奥波德·布卢姆,一个广告推销员和社会局外人。这一天是工作日,所以布卢姆和史蒂芬分别离开家,开始他们在都柏林的旅程。

《尤利西斯》包含了丰富详细的故事,虽然被普遍描述为一部小说,但它打破了许多与小说形式相关的界限。它由十八章节或“插曲”组成,每个插曲都在某种程度上呼应了荷马史诗《奥德赛》中的一个场景。每个插曲发生在不同的背景下,每个插曲都以不同的风格写成,通常是不寻常的风格。这本书的主要创新通常被认为是其扩展了乔伊斯在前两本书中使用的“自由间接话语”或“内心独白”技巧。
《尤利西斯》不仅以其形式的新颖和语言的创新而闻名,还以其传奇般的出版历史而闻名。该书的前十四个插曲在 1918 年至 1920 年间分期连载在《小评论》上,而几个插曲在 1919 年发表在《自我主义者》上。1921 年,纽约反淫秽协会在第十三个插曲“诺西卡”中赢得了一场关于淫秽的审判。《小评论》的编辑被禁止再发表任何后续章节;《尤利西斯》直到 1934 年才再次出现在美国。
这部小说最初的接受程度褒贬不一。威廉·巴特勒·叶芝称其为“疯狂”,但后来同意了 T·S·艾略特和埃兹拉·庞德的积极评价,称其为“无疑是一部天才之作”。乔伊斯的第二位传记作者理查德·埃尔曼报告说,一位医生声称曾看到他疯狂患者写的同等水平的作品,弗吉尼亚·伍尔夫则嘲笑它为“粗俗”。乔伊斯的姑姑约瑟芬·默里因其据称的淫秽而拒绝阅读,对此乔伊斯著名地回应说,如果是这样,那么生活本身就不值得一读。
文本中的丰富参考使《尤利西斯》成为一本几乎要求读者进行批判性解读的书籍;但也使它成为一本很容易被过去一个世纪以来产生的学术研究所掩盖的书籍。对严肃解读的否定是诱人的,但会将乔伊斯庞大的项目贬低为一个长篇笑话或一个复杂的自我锻炼。同样地,将其视为无法解释的也会忽略大量认真的批评分析。
今天,许多人认为《尤利西斯》是 20 世纪文学的巅峰之作:是有史以来写成的最丰富、也是最困难的书之一。欣赏它并不意味着认为它晦涩难懂;相反,也许最好的描述是在 21 世纪对荷马史诗中尤利西斯本人使用的一个描述——“复杂”。
这个标准电子书版本基于 1922 年巴黎莎士比亚书店首版的抄写本,修正了 1929 年前的勘误表和 1927 年第九次印刷的第二版。它并不追踪任何特定版本,而是一个融合了 1929 年前版本的版本,旨在包含学者们认为在 1929 年前印刷的最准确版本。因此,保留了一些可能已在 1929 年后版本中纠正的错误印刷。建议在联系标准电子书有关潜在错误之前,查阅该书的各种版本和附在汉斯·瓦尔特·加布勒的《批判性和综合版》后的历史校对清单。
这本书的源代码在 GitHub 上,任何人都可以为使标准电子书更好而做出贡献!如果您发现错别字、排版错误或其他错误,请查看如何报告错误。如果您熟悉技术并希望直接做出贡献,请查看这本电子书的 GitHub 存储库和我们的贡献者部分。您也可以捐赠给标准电子书,帮助资助持续改进这本书和其他电子书。
HN 评论 104 comments | 作者:robin_reala | 7 hours ago #
https://news.ycombinator.com/item?id=40535895
- 有人认为将自动产生的机器阅读评分放在网站上是不尊重用户的,因为它可能给读者提供错误的信息,认为机器评分会替代人类智慧的注释,而这是一种危险的文化趋势。
- 有人提到在中国引进《尤利西斯》时,出版商和评论家通常认为这本小说很具挑战性,原因包括大量运用意识流、复杂的内心独白、多种语言和习语以及丰富的词汇。
- 另一人认为阅读评分虽然存在缺陷,但是被广泛接受,并指出机器评分只是一种有限的启发式方法,适合在 Standard Ebooks 中使用,即使它并非百分之百正确。
- 有人提供了在阅读《尤利西斯》时的有效阅读方法,建议先在纸上阅读,然后结合网站上的注释进行阅读。
- 有人对 Standard Ebooks 项目表示感激,认为这是一项重要的项目,为公有领域的电子书提供了高质量、可访问、免费的版本。
- 还有人指出即使一些付费电子书质量低下,Standard Ebooks 的电子书质量非常好。
- 有人建议将 Hans Walter Gabler 的书《批判与概要版》数字化,以方便比较不同版本,但意识到这需要巨大的工作量。
- 有人认为读者可以以任何方式接触《尤利西斯》,而不必被门卫阻挡。
- 有人对 Standard Ebooks 网站的排序功能提出了改进建议,希望能够按标题进行排序。
- 关于 Standard Ebooks 和 Gutenberg.org 之间的合作,有人提到两者的使命不同,但彼此之间进行了交流,也有可能共享一些电子书资源。
“Imprecise” language models are smaller, speedier, and nearly as accurate #
https://spectrum.ieee.org/1-bit-llm
本文介绍了大型语言模型(LLMs),这些 AI 系统驱动着诸如 ChatGPT 之类的聊天机器人,它们变得越来越强大,但也变得越来越庞大,需要更多能源和计算能力。为了让 LLMs 便宜、快速且环保,它们需要缩小,最好足够小以直接在诸如手机之类的设备上运行。研究人员正在通过将存储其记忆的许多高精度数字大幅舍入为 1 或 - 1 来找到实现这一目标的方法。
LLMs,如所有神经网络一样,是通过改变其人工神经元之间的连接强度来进行训练的。这些强度被存储为数学参数。研究人员长期以来一直通过降低这些参数的精度来压缩网络,这个过程称为量化,这样每个参数的占用空间可能从 16 位减少到 8 位或 4 位。现在研究人员正在推动极限,将其压缩到只有一个位。

有两种一般方法来制作 1 位 LLM。一种方法称为后训练量化(PTQ),是将完整精度网络的参数量化。另一种方法,量化感知训练(QAT),是从头开始训练一个具有低精度参数的网络。到目前为止,PTQ 在研究人员中更受欢迎。
在今年 2 月,包括苏黎世联邦理工学院的秦浩桐、北京航空航天大学的刘祥龙和香港大学的黄伟在内的一个团队推出了一种名为 BiLLM 的 PTQ 方法。它使用 1 位来近似网络中的大多数参数,但使用 2 位来表示一些显著权重,即对性能最有影响的权重。在一个测试中,该团队对 Meta 的具有 130 亿参数的 LLaMa LLM 版本进行了二值化。
评估性能时,研究人员使用一个称为困惑度的指标,它基本上是评估训练模型对每个随后的文本片段感到惊讶程度的指标。对于一个数据集,原始模型的困惑度约为 5,而 BiLLM 版本的得分约为 15,远远好于最接近的二值化竞争对手,其得分约为 37(对于困惑度,数字越低越好)。然而,BiLLM 模型所需的内存容量约为原始模型的十分之一。
Harbin Institute of Technology 的计算机科学家车万祥表示,PTQ 比 QAT 具有几个优势。它不需要收集训练数据,也不需要从头开始训练模型,训练过程更加稳定。然而,QAT 有潜力使模型更加准确,因为量化是从一开始就内置到模型中的。
去年,微软亚洲研究院的魏富如和马树明领导的团队开发了 BitNet,这是第一个用于 LLMs 的 1 位 QAT 方法。通过调整网络调整参数的速率,以稳定训练,他们创建了性能优于使用 PTQ 方法创建的 LLMs 的模型。它们仍然不如完整精度网络表现好,但大约是其能效的 10 倍。
今年 2 月,魏的团队宣布了 BitNet 1.58b,其中参数可以等于 - 1、0 或 1,这意味着它们大约占据了每个参数 1.58 位的内存。一个具有 30 亿参数的 BitNet 模型在各种语言任务上表现与具有相同数量参数和训练量的完整精度 LLaMA 模型相当,但它的速度提高了 2.71 倍,GPU 内存使用减少了 72%,GPU 能量使用减少了 94%。魏称之为 “顿悟时刻”。此外,研究人员发现,随着训练更大的模型,效率优势会增加。
今年,哈尔滨工业大学的车万祥领导的团队在另一种 LLM 二值化方法,称为 OneBit,上发布了一篇预印本。OneBit 结合了 PTQ 和 QAT 的元素。它使用完整精度的预训练 LLM 来生成用于训练量化版本的数据。该团队的 130 亿参数模型在一个数据集上实现了困惑度约为 9,而具有 130 亿参数的 LLaMA 模型的困惑度为 5。与此同时,OneBit 仅占用原模型 10%的内存。在定制的芯片上,它可能运行得更快。
微软的魏表示,量化模型具有多个优势。它们可以适应更小的芯片,需要更少的内存和处理器之间的数据传输,并允许更快的处理。然而,目前的硬件无法充分利用这些模型。LLMs 通常在诸如 Nvidia 制造的 GPU 上运行,这些 GPU 使用更高精度表示权重,并且大部分能量花费在对它们进行乘法运算。新硬件可以本地表示每个参数为 - 1 或 1(或 0),然后简单地进行加减运算,避免乘法。魏表示,“1 位 LLMs 为专门优化为 1 位 LLMs 的新硬件和系统设计打开了新的大门”。
“1 位模型和处理器应该一起成长”,香港大学的黄表示。“但要开发新硬件还有很长的路要走”。
HN 评论 149 comments | 作者:jnord | 23 hours ago #
https://news.ycombinator.com/item?id=40529355
- 作者认为,量化模型并不是免费的,尤其是 llama3 模型在量化时会比 llama2 模型受到更严重的质量损失,这可能是因为 llama 模型在训练过程中没有充分利用每个权重。
- 在 llama3-8b 的情况下,量化后可能会变得更脆弱,但在 llama3-70b 中的表现却出人意料地好,即使在每个参数使用 2-3 位时也能保持良好表现。
- 人工神经网络的量化是指使用更紧凑的权重表示方式,这样可以加快模型运行速度,但在信息丢失的情况下仍然能产生体面的结果。
- 量化并非捷径,而是一种测试,更多的训练会导致更好的压缩。
- 有人建议通过提取网络的对称不变性来进一步压缩网络的大小,但这可能取决于具体的神经网络架构。
- 对于特定任务,90% 准确的模型可能会变得毫无用处,而 99% 准确的模型却相当有用。
- 目前的实验表明,通过组合多个弱模型,可以产生任意强大的预测 / 生成器,但将这些技术应用于大型语言模型仍面临挑战。
- 在训练小型模型以及训练代理程序方面可能更为明智,而不是试图使一个模型在所有领域都表现优异。
- 作者认为,虽然人类很难达到 99.9% 的准确率,但不久之后就可能会信任模型比人类专家更多。
- 对于模型是否能够达到完美准确性,观点不一,因为人们对 “完美” 的定义可能会有所不同。
- 训练模型理解语言,然后再搜索网络或查询数据库以获取答案可能是更合适的方法,而不是将所有人类知识都塞入模型中。
How to copy a file from a 30-year-old laptop #
https://www.unterminated.com/random-fun/how-to-copy-a-file-from-a-30-year-old-laptop
这篇文章讲述了如何从一台 30 年前的苹果笔记本电脑中复制文件的过程。文章作者面临了一些挑战,因为这台 1994 年的 PowerBook Duo 280c 笔记本电脑存有一些他想要保存的音频录音,但由于设备的特殊性,传输文件并不容易。

作者通过使用传真软件和一些创造性的方法,最终成功地将音频文件从这台老旧笔记本电脑中复制出来。整个过程包括使用资源编辑器 ResEdit 查看文件的十六进制内容,将文件内容通过传真发送到另一台计算机,然后通过光学字符识别(OCR)将传真接收的图像转换回二进制文件。
最终,作者成功地将音频文件转换为可播放的格式。整个过程展示了作者在面对技术挑战时的创造性解决方案和坚持不懈的精神。
HN 评论 147 comments | 作者:tfvlrue | 6 hours ago #
https://news.ycombinator.com/item?id=40536436
- 一些评论认为可以使用串口传输文件,而不是使用传真机;
- 另一些评论提到应该使用更大的字体来提高 OCR 的准确性;
- 有人建议直接连接 DSO 到扬声器端口来录制音频数据;
- 还有评论指出可以使用 USB 到 SCSI 适配器来读取硬盘数据;
- 有人提到可以使用 Appletalk 进行文件传输;
- 还有评论认为作者应该更深入地探索硬盘连接器,并尝试读取文件系统。