- 15 次围观
2024-05-29 Hacker News Top Stories #
- WordPress成立21周年,其成功归功于易用性、社区贡献等关键因素。
- Tantivy是一个受Apache Lucene启发的Rust编写的全文搜索引擎库,适用于现代项目。
- 在单个GPU上复现GPT-2模型的讨论,包括训练时间、成本和技术细节。
- 美国城市中非营利组织工业复合体对城市腐败的影响,税收被挥霍在私人合同上。
- Grooved是一个免费应用程序,通过播放一首歌帮助校准唱机速度,注重隐私保护。
- Gh-dash是一个美观的命令行界面仪表板,用于管理和查看GitHub上的Pull Request和Issues。
- 软件开发中实际操作与学习过程的分布特性,学习过程的不确定性对项目管理的影响。
- 论文研究Transformers模型是否能够学会隐式推理,通过深度训练实现隐式推理。
- Mobifree是一个开源移动生态系统,旨在独立于大科技巨头,包括操作系统、应用商店等。
- More Itertools是一个扩展Python itertools模块的库,提供更多处理可迭代对象的工具和函数。
WP21 #
这篇文章是由 Matt Mullenweg 撰写的,标题为“WP21”。文章提到了 WordPress 成立 21 周年,回顾了 Mike 和 Matt 发布 WordPress 的初衷,即基于 b2/cafélog 的分支。文章列举了 WordPress 成功的元素,包括简单易用的操作、博客、评论和 pingbacks 的趣味性、动态网站的优势、易于编辑的维基文档等。
此外,文章还提到了对社区的重视、主题和插件的基础设施、反馈机制的重要性以及核心功能的独特性等方面。最后,文章还分享了一些趣闻,包括 WordPress 的成长历程和对软件发展的见解。
HN 评论 163 comments | 作者:joshbetz | 20 hours ago #
https://news.ycombinator.com/item?id=40496858
- WordPress 的开发标准值得遵循,但现在却鼓励破坏标准,全局变量随处可见,经典主题鼓励混乱的代码结构,新主题也在犯同样的错误,将 JSON 放在 HTML 注释中,这些决定令人失望。
- WordPress 的“永不破坏向后兼容性”的原则是双刃剑,对非技术用户友好,但也导致无法改变过去的技术决策。
- WordPress 的发展方向令人失望,新的开发努力也在做出糟糕的决定,如将模板标记放在 HTML 注释中作为 JSON。
- WordPress 对于自由职业者来说是个好选择,但对于高端网站,企业端需求增长迅猛,需要更多能够处理大客户的机构和开发者。
- WordPress 对于用户来说简单易用,用户和开发者对“简单”有不同理解,对于用户来说,WordPress 简单,对于开发者来说,WordPress 复杂。
- WordPress 的生态系统和社区是其优势,虽然有缺点,但难以撼动,开发者和用户共同推动了其发展。
- WordPress 的历史和遗留问题导致其难以现代化,但其稳定性和向后兼容性也是其优势之一。
- WordPress 的生态系统和插件费用可能会影响其地位,高昂的插件许可费用可能成为用户的负担。
- WordPress 虽然有安全问题,但主要是由于 Linux 和 PHP,其他开源项目也存在严重漏洞,但很少被人关注。
- WordPress 的锁定效应使得用户难以迁移,对于建立业务的用户来说,迁移成本可能很高,而且插件许可费用也是一个问题。
- WordPress 的稳定性和向后兼容性对 PHP 的发展有影响,稳定性是好事,不必因为与现代品味不符的代码而进行更改。
- WordPress 的稳定性对 PHP 的发展有积极影响,新版本的破坏性变化对于已建立的项目来说是噩梦。
Tantivy – full-text search engine library inspired by Apache Lucene #
https://github.com/quickwit-oss/tantivy
Tantivy 是一个受 Apache Lucene 启发、用 Rust 编写的全文搜索引擎库。它不同于 Elasticsearch 或 Apache Solr,而更像 Apache Lucene,是一个可用于构建搜索引擎的 crate。

Tantivy 的设计受到 Lucene 的强烈启发。其特点包括全文搜索、可配置的分词器(支持 17 种拉丁语言的词干处理,同时有第三方支持中文、日文和韩文等语言的分词器)、快速启动时间(
Tantivy 不支持分布式搜索,但如果需要此功能,可以查看 Quickwit。Tantivy 支持稳定的 Rust 版本,适用于 Linux、macOS 和 Windows。用户可以通过 tantivy-cli 创建搜索引擎、索引文档,并通过 CLI 或 REST API 进行搜索。此外,还提供了最新版本的参考文档、支持项目的多种方式以及贡献代码的方法。
HN 评论 54 comments | 作者:kaathewise | 1 day ago #
https://news.ycombinator.com/item?id=40492834
- Tantivy 是一个快速的全文搜索引擎库,适合现代项目,比 Lucene 更推荐。
- PostgreSQL 的全文搜索功能不错,但在排名支持方面有限,不如 Lucene 或 Tantivy。
- Tantivy 在 ParadeDB 中使用,替代 Elastic,对多语言搜索效果好。
- Quickwit 基于 Tantivy,适用于处理数十亿对象的索引,性能优秀,支持分离计算和存储。
- Tantivy 在 LanceDb 中提供全文搜索功能,是一个有趣的向量数据库产品。
- Tantivy 在小数据集情况下比 Solr 更现代,效率更高。
- Tantivy 适合替代 Postgres FTS,性能好,适用于大数据集。
- Tantivy 是一个出色的技术,用于实现 OLTP 全文搜索,代码结构良好。
- Tantivy 编译成 wasm,用于浏览器中,可为静态网站提供快速搜索功能。
- Tantivy 可能不适合所有情况,与向量数据库结合使用效果更好,称为混合搜索。
- 全文索引类似于高度专业化的向量数据库,适用于“词袋”表示的文档和查询。
- Infinity 结合了向量搜索和全文搜索,提供极快的搜索性能。
Reproducing GPT-2 in llm.c #
https://github.com/karpathy/llm.c/discussions/481
这个讨论是关于在 llm.c 中复现 GPT-2 (124M) 模型的过程。作者提到了使用 llm.c 在 90 分钟内以约 20 美元的成本复现这一模型的方法。他描述了在单个 8X A100 80GB SXM 节点上使用 llm.c 在约 90 分钟内复现该模型的过程。
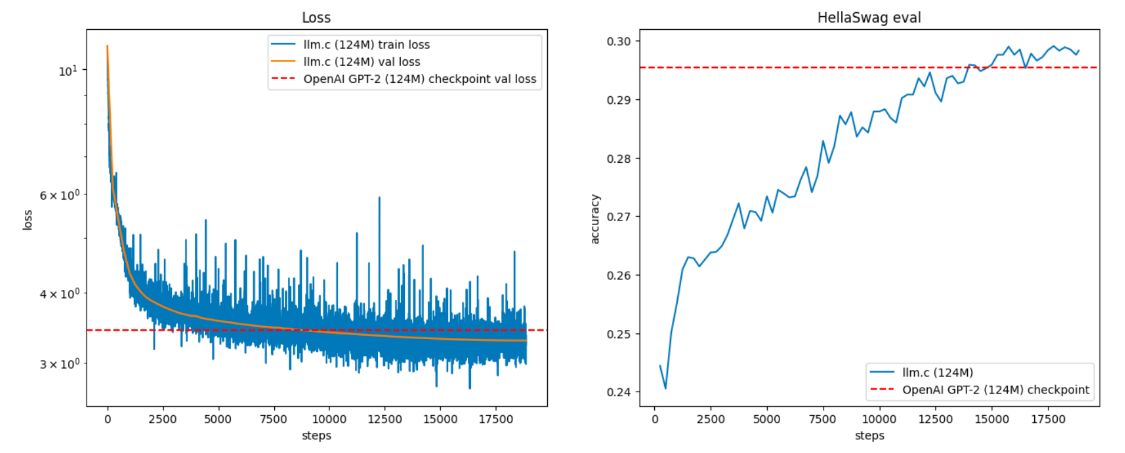
作者还提到,可以使用单个 GPU 训练模型,但需要相应延长训练时间(例如,使用不同 GPU 大约需要 4-24 小时)。讨论中还包括了关于训练过程、参数设置、优化指南以及如何进行条件生成等详细信息。此外,作者还提到了如何安装和配置所需的软件环境,以及如何进行数据预处理和模型训练。讨论中还包含了一些用户的评论和问题,以及作者对这些问题的回答和解释。
HN 评论 57 comments | 作者:tosh | 6 hours ago #
https://news.ycombinator.com/item?id=40502090
- 评论中提到 llm.c 是为了实现直接的 C/CUDA 实现,追求简洁、最小依赖、教育性质;
- 有人询问 llm.c 与 nanoGPT 的性能差异,karpathy 表示 llm.c 稍快,计划进一步提升;
- 讨论了 GPT-3 Ada 训练成本,karpathy 估计训练 GPT-3 Ada 大约需要 2000 美元;
- 讨论了 llm.c 的二进制文件大小,目标是构建更小的训练/微调堆栈;
- 讨论了 Llama3 架构的性能改进,karpathy 认为改进并不像想象中那么大;
- 讨论了数据集获取和版权问题,以及对数据集付费的看法;
- 讨论了在没有 GPU 的旧机器上运行 llm.c 模型的推理性能。
The Nonprofit Industrial Complex and the Corruption of the American City #
这篇文章探讨了美国城市中的非营利组织工业复合体,以及它们对城市的腐败影响。文章指出,许多城市通过提高税收来资助公共服务,但这些税收却被挥霍在私人合同上,这些合同是给无法追究责任的非营利组织,它们的活动往往无助于解决问题。
文章提到了一些案例,如旧金山的 Tenants and Owners Development Corporation(todco),尽管名字中包含“发展”一词,却在过去 20 年未开发任何财产,而是将资金用于提高高管薪酬和游说。此外,todco 还通过游说阻止在一些昂贵社区建造经济适用房,与其宣称的目标相悖。文章还提到了一些非营利组织的腐败行为,如雇佣前罪犯、挪用资金等,以及政府对这些组织的监管不足。
最后,文章指出,这些问题不仅存在于旧金山,还在其他城市中普遍存在,进一步强调了私人非营利组织在城市治理中的负面影响。
HN 评论 215 comments | 作者:lalaland1125 | 19 hours ago #
https://news.ycombinator.com/item?id=40497106
- 评论指出非营利组织可能存在滥用公共资金的情况,缺乏足够监督保证其履行职责;
- 评论提到西雅图存在类似情况,资金被转移到一些组织,但缺乏跟踪,导致城市核心需求被忽视;
- 评论指出,对于缺乏经济激励维持现状的问题,应该朝着促进更多市场价格的经济适用房屋政策和解决方案努力;
- 评论提到芬兰在解决无家可归问题上取得成功,通过创新社会计划减少了无家可归人口;
- 评论指出,芬兰拥有许多创新的社会计划,如痴呆村和开放监狱项目;
- 评论认为芬兰的成功可能不适用于其他地方,因为问题规模不同,政策制定存在差异。
Show HN: I made a free app to calibrate your turntable by simply playing a song #
网站 https://grooved.okat.best 是一个免费且无广告的网站。该网站介绍了一个帮助校准唱片机的应用程序,名为 Grooved。文章中提到了对于营销文案变得过于自我意识的看法,以及对于公司身份变成一系列与行业相关但缺乏幽默的短语集合的观察。

作者还谈到了早期 iPhone 应用程序的单一功能和单一用途的兴奋感,以及对于 Grooved 应用程序的介绍和如何使用它来校准唱片机的速度。同时,强调了 Grooved 不会收集任何数据,所有音频流在用户设备上本地处理,不会被记录。该应用程序也没有使用第三方库或 API,仅使用了苹果提供的内置组件。
HN 评论 147 comments | 作者:okatbest | 8 hours ago #
https://news.ycombinator.com/item?id=40501021
- 有评论提到在录制音乐时可能会出现定时错误,导致唱片速度不同;
- 有人分享了使用 Audacity 这种工具来修复音乐文件中的音高问题;
- 有评论讨论了录音时可能出现的速度变化问题;
- 有人提到一些音乐录制不一定遵循 A 440 Hz 的标准;
- 有评论讨论了使用数字母带制作音乐时的速度调整问题;
- 有人分享了使用手机应用来测量唱片转速的经历;
- 有评论提到唱片播放速度可能会因唱片孔不在中心位置而产生波动;
- 有人分享了使用手机应用来校准唱片速度的体验;
- 有评论讨论了唱片播放速度的校准方法。
Gh-dash: A beautiful CLI dashboard for GitHub #
https://github.com/dlvhdr/gh-dash
这个 GitHub 仓库( https://github.com/dlvhdr/gh-dash)包含一个名为“gh-dash”的美观 CLI 仪表板,用于 GitHub。该仪表板具有以下特点:
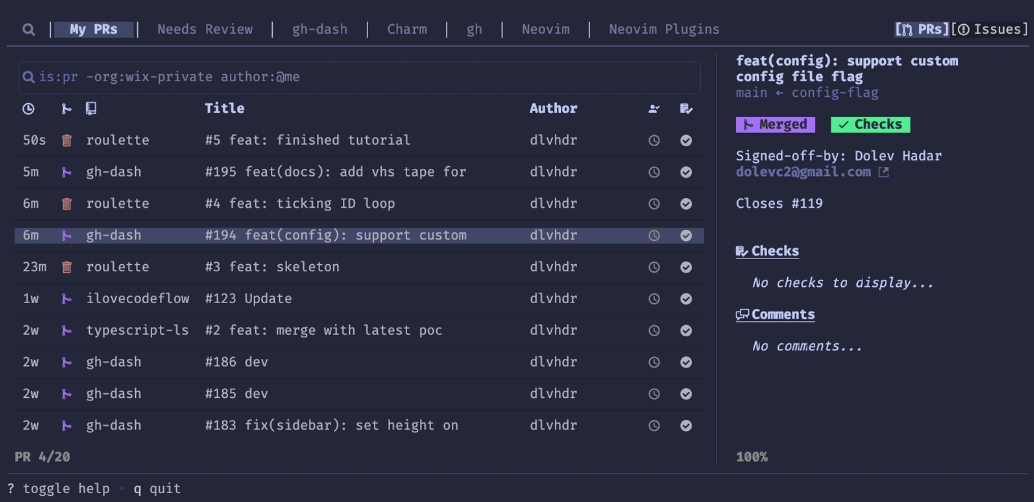
- 完全可配置 - 使用 GitHub 筛选器定义部分
- 可搜索 PR 和问题
- 可自定义列,包括隐藏、宽度和增长属性
- 可对 PR 和问题执行操作,如检出、评论、打开、合并、差异等
- 可设置自定义操作与新的键绑定
- 可使用自定义主题
- 可查看有关 PR/问题的详细侧边栏信息
- 可编写多个配置文件,轻松切换完全不同的仪表板
- 可设置自动刷新仪表板的间隔
安装方式:
- 安装 gh CLI - 参见安装说明
- 安装此扩展:gh extension install dlvhdr/gh-dash
- 为了正确显示图标,您应下载并安装 Nerd 字体,然后将其设置为终端的字体
使用方式:
- 运行 gh dash,然后按?获取帮助
- 运行 gh dash –help 获取更多信息
配置方式:
- 通过 config.yml 文件定义部分,包括标题和筛选器
- 所有配置位于扩展目录下的 config.yml 文件中
- 可定义自定义键绑定和主题
此仪表板由 Dolev Hadar 创建,用于创建 GitHub 的美观 CLI 仪表板。
HN 评论 59 comments | 作者:robenkleene | 22 hours ago #
https://news.ycombinator.com/item?id=40496150
- 评论中提到了对于 CLI 工具的设计趋势和喜爱 Charm 框架的看法;
- 有人讨论了 Go 在 TUI 领域的优秀表现以及 GUI 领域的不足;
- 关于 Fyne 和 Textualize.io 的讨论,以及对于 TUI 和 GUI 的偏好;
- 有人提到了在终端显示视频和图片的方法;
- 讨论了 Python 的静态构建和 JS 的可执行文件生成;
- 有人分享了关于自定义 GitHub 过滤视图的项目,并邀请测试;
- 讨论了 Gitlab 的类似工具以及对于自托管 GitHub API 兼容解决方案的需求;
- 有人谈到了中心化与去中心化技术的发展路径和趋势。
Doing is normally distributed, learning is log-normal #
https://hiandrewquinn.github.io/til-site/posts/doing-is-normally-distributed-learning-is-log-normal/
这篇文章讨论了一个有趣的概念:在软件开发中,实际操作通常服从正态分布,而学习过程则服从对数正态分布。作者以“漏斗管道”理论为例,说明了这一点。比如,当你在开发一个 Laravel 网络应用时,你可能对如何启动应用有 90% 的把握,对处理在线基础设施有 80% 的把握,对获取第一个客户有 70% 的把握。但是,从零到第一个客户成功的几率是多少呢?计算结果是 0.9 * 0.8 * 0.7,略高于 0.5,这个结果可能没有之前的数字那么令人鼓舞。
软件估算之所以混乱,部分原因在于它难以认识到,至少在某种程度上,即时学习并非服从正态分布。传统项目管理中的一切,从瀑布模型到甘特图再到估算实践,都基于一个假设:链条中的每个步骤都呈钟形分布。然而,在对数正态分布中,花费两倍、三倍甚至五倍时间的过程更为常见,这打乱了一切。有些事情比通常快得多,但是在原定一周完成的项目中花一半时间,另一个项目却花了原定时间的两倍,最终你的时间预算仍然不够。
在软件开发中,几乎从不可能事先了解你将在开发过程中面临的所有或大部分技术障碍。这种“漏斗管道”方法可以揭示一些关于我们行业的更加反直觉的事情,比如对相关经验以及申请特定工作时了解特定工具的强调。每个人都需要经历至少一段由学习主导的阶段,这对于网页开发和操作麦当劳的驶入窗口一样适用。需要特殊的严谨性才能将这种学习转化为一种活动常规和可重复性足够高,以至于你能获得一个长尾的正态分布、盈利性活动。
总的来说,这篇文章强调了在软件开发中,学习过程和实际操作之间的差异,以及如何理解和应对这种差异。
HN 评论 69 comments | 作者:hiAndrewQuinn | 17 hours ago #
https://news.ycombinator.com/item?id=40497623
- 评论中提到,软件估算混乱部分在于难以认识到即时学习至少是非正态分布的事实。
- 有人认为,在传统项目管理中,对学习的认知不足,假设学习是一个次要部分。
- 讨论中提到,软件估算困难不仅存在于软件领域,也存在于建筑、交通、国防等领域。
- 评论指出,软件估算混乱部分在于很少讨论概率,而三点估算等统计方法可能更有效。
- 讨论中提到,软件开发中的“试错”思想类似于化学工程中的“试验装置”概念。
- 评论中提到,游戏开发中的“垂直切片”类似于“试验装置”,用于验证创作流程。
- 有人认为,软件和化学工程中的不确定性不同,软件需要采取快速失败的迭代方法。
- 引用 Fred Brooks 的观点,强调计划建立一个“试验系统”,因为最终会这样做。
- 讨论中提到,软件开发中的“第二系统效应”指的是在第二个系统中复制第一个系统的所有功能,导致过度工程化。
- 讨论中提到,Fred Brooks 对自己的观点感到惊讶和悲哀,认为软件项目管理领域似乎没有取得太多进展。
- 评论中提到,软件开发领域需要更多的系统性学习,以超越 Fred Brooks 的观点。
Grokked Transformers Are Implicit Reasoners #
https://arxiv.org/abs/2405.15071
这篇论文的标题是《Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization》,作者为 Boshi Wang、Xiang Yue、Yu Su 和 Huan Sun。论文研究了 transformers 是否能够学会隐式推理参数化知识,这是即使最强大的语言模型也难以掌握的技能。
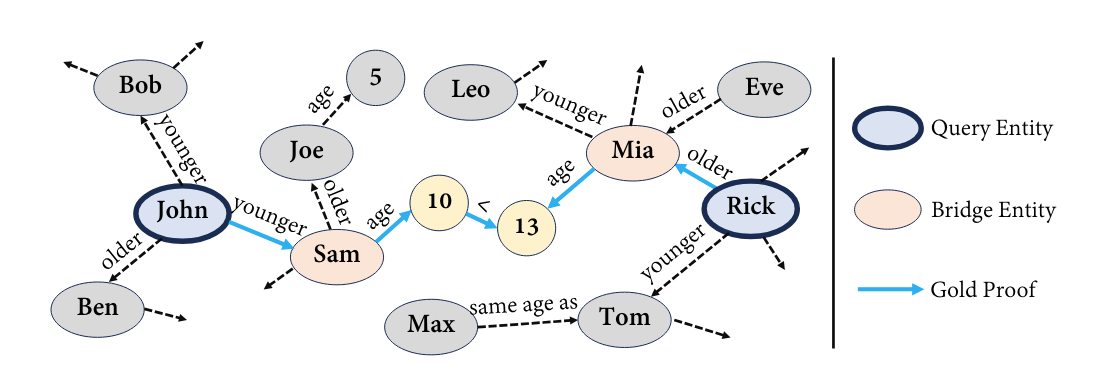
研究集中在两种代表性的推理类型上,即组合和比较,发现 transformers 可以学会隐式推理,但只能通过深度训练才能实现,即超出过拟合的范围。推理类型的泛化水平也因类型而异:当面对超出分布的示例时,transformers 在组合方面无法系统地泛化,但在比较方面成功实现泛化。
研究人员在整个训练过程中深入研究了模型的内部情况,进行了分析实验,揭示了:1)grokking 背后的机制,例如泛化电路的形成及其与泛化和记忆电路的相对效率之间的关系,以及 2)系统性与泛化电路配置之间的联系。研究结果指导数据和训练设置,以更好地诱导隐式推理,并提出了改进 transformer 架构的潜在方法,例如鼓励跨层知识共享。
此外,研究人员还证明,对于一个具有大搜索空间的具有挑战性的推理任务,基于非参数化记忆的 GPT-4-Turbo 和 Gemini-1.5-Pro 无论采用何种提示风格或检索增强,都表现不佳,而一个完全 grokked 的 transformer 可以实现接近完美的准确性,展示了参数化记忆在复杂推理中的强大作用。
HN 评论 58 comments | 作者:jasondavies | 1 day ago #
https://news.ycombinator.com/item?id=40495149
- 对于 AI 中心问题,评论者认为我们目前陷入了一个局部最小值,需要关注 grokking 并找出如何帮助它,研究如本文非常重要。
- 有人认为训练数据分布而非大小对泛化行为有质的影响。
- 评论者建议寻找惩罚形成记忆和插值电路的架构,而不是仅仅治标不治本。
- 讨论了 Google 搜索的问题,指出使用廉价模型导致结果尴尬,而顶尖模型可能效果更好。
- 有人提到 grokking 与《The Dip》中概念类似,强调成功者通常通过艰难阶段。
- 有人认为这篇论文过于抽象,难以理解作者实际做了什么。
- 评论者对论文中的推理过程提出质疑,指出可能存在简单模式被机器学习算法发现的情况。
- 讨论了关于 grokking 和 double descent 的区别,以及模型训练过程中的一些有趣结果。
- 论文中的结果表明,GPT-2 大小的 transformer 在连接事实方面远远超过了 GPT4 和 Gemini 1.5。
- 论文中提到的关于因果追踪和泛化电路的内容也引起了评论者的兴趣和讨论。
Mobifree – An open-source mobile ecosystem #
https://f-droid.org/2024/05/24/mobifree.html
这篇文章介绍了一个名为 Mobifree 的开源移动生态系统,旨在提供一个与大科技巨头和门户网站无关的移动生态系统。Mobifree 包括操作系统、应用商店、云服务、消息应用、电子邮件服务器等,致力于保护用户隐私、倡导民主和健康竞争,并依赖开源解决方案推动其软件。

文章指出当前移动生态系统由少数大科技公司主导,对用户、开发者和政府都施加了限制和数据追踪,因此需要一个新的替代方案。F-Droid 是 Mobifree 项目的合作伙伴之一,致力于提供开源、以隐私为导向的解决方案。Mobifree 旨在为用户和开发者构建一个以道德实践、数字主权、公平、可持续性和包容性为中心的移动体验。F-Droid 将在项目中发挥重要作用,创建一个分散的应用程序分发系统,为开发者向 Android 用户提供应用程序。该系统将提供用户隐私控制、增加透明度,并为用户提供真正的应用程序和应用商店选择。
欢迎各种形式的支持,包括社区参与、法律支持、开发者、研究人员和最终用户。如果您对参与 Mobifree 运动感兴趣,请访问 f-droid.org 了解更多信息。
HN 评论 119 comments | 作者:jrepinc | 8 hours ago #
https://news.ycombinator.com/item?id=40501027
- F-Droid 仍需一些大任务才能成为适合普通大众使用的,与 Google Play Store 相比。
- F-Droid 搜索似乎无法理解“浏览器”是什么,导致搜索结果不准确,需要滚动很久才能找到想要的应用。
- 政策阻碍 F-Droid 成为可行的替代品,无法完全取代 Google Play Store。
- F-Droid 可作为应用商店的一个扩展,但不足以成为替代品。
- F-Droid 不包含专有软件是其优势和存在理由。
- F-Droid 作为一个平台发布应用,开源要求使其无法成为替代品。
- F-Droid 无法提供支付功能,但可能会考虑出于道德原因提供。
- Mobifree 项目旨在为移动应用提供分散式分发系统。
- F-Droid 提供的应用通常是开源且无广告、无追踪等,是一个值得支持的平台。
- F-Droid 是一个分发 Android 应用的替代品。
- F-Droid 是一个开源项目,依赖于欧盟资助。
- 欧盟资助可能对技术项目产生负面影响。
- 欧盟资助可能导致项目只服务欧盟公民。
- F-Droid 并非地理限制,但文章中的描述可能是为了欧洲市场的营销推动。- F-Droid 仍需一些大任务才能成为适合普通大众使用的,与 Google Play Store 相比。
- F-Droid 搜索似乎无法识别“浏览器”,导致 Fennec 无法显示。
- F-Droid 受政策限制,无法完全替代 Google Play Store,只能作为额外商店。
- F-Droid 作为应用来源之一,对于无法进入 Play Store 的应用(如 AdAway、NewPipe 和 Termux)已经是一个可行的替代方案。
- F-Droid 的政策使得发布游戏变得困难,因为缺乏可接受的开源游戏商业模式。
- F-Droid 作为一个不追踪、提供替代方案、不增强 Google-Apple 移动市场垄断的平台,被视为一种选择。
- F-Droid 可以添加第三方存储库,但用户体验可能有所不同。
- Mobifree 项目旨在为移动应用提供分散式分发系统,包括 F-Droid 在内。
- F-Droid 提供的应用通常是开源且无广告、无追踪等,是一个可靠的选择。
- Mobifree 项目得到欧洲委员会 Next Generation Internet (NGI) 计划的资助。
More Itertools #
https://more-itertools.readthedocs.io/en/stable/
更多迭代工具(More Itertools)是一个 Python 库,旨在扩展标准库中的 itertools 模块,提供了更多用于处理 Python 可迭代对象的构建块、配方和常用例程。该库包含了多个功能模块,涵盖了各种操作,包括但不限于:
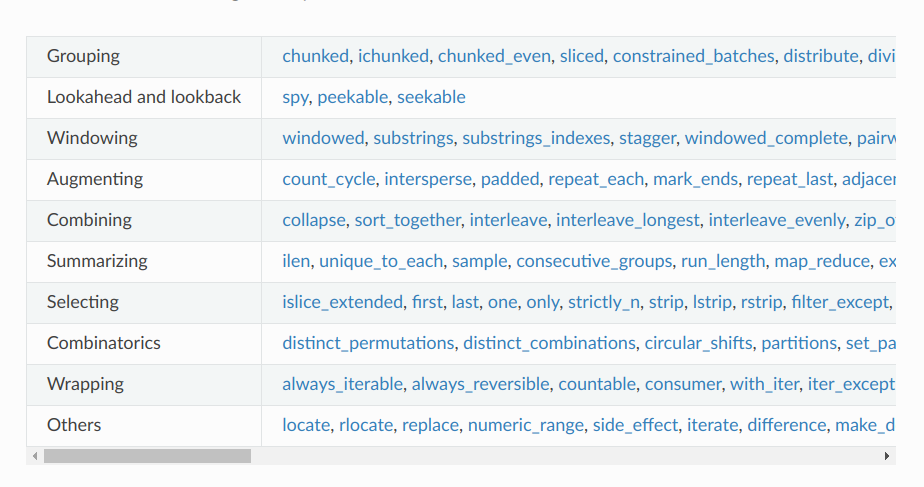
- 分组:提供了一系列函数用于对可迭代对象进行分组,如 chunked、ichunked、chunked_even 等;
- 预览和回溯:包括 spy、peekable、seekable 等函数,用于查看可迭代对象的下一个元素;
- 窗口处理:提供了处理窗口数据的函数,如 windowed、substrings、stagger 等;
- 增强功能:包括 count_cycle、intersperse、padded 等函数,用于增强可迭代对象的功能;
- 合并:提供了多个函数用于合并可迭代对象,如 collapse、sort_together、interleave 等;
- 汇总:包括 ilen、unique_to_each、sample 等函数,用于对可迭代对象进行汇总处理;
- 选择:提供了一系列函数用于选择可迭代对象的特定元素,如 islice_extended、first、last 等;
- 组合数学:包括 distinct_permutations、distinct_combinations、partitions 等函数,用于组合数学操作;
- 其他功能:提供了多个其他功能函数,如 locate、replace、difference 等。
你可以通过 pip 安装 more-itertools 库,并使用其中的函数来处理各种可迭代对象。该库还包含了 itertools 文档中的配方,并提供了一些新的配方函数。详细的函数列表和用法可以在 API 文档中找到。
HN 评论 45 comments | 作者:stereoabuse | 1 day ago #
https://news.ycombinator.com/item?id=40493074
- 实用性观点:更_itertools 提供了方便的迭代器功能,简化了代码实现。
- 单元测试观点:more_itertools.one 函数在单元测试中特别有用,简化了代码结构。
- 库推荐观点:建议查看 “boltons” 库,提供了应该内置在 Python 中的功能。
- 标准库观点:希望将 more_itertools 引入标准库,减少对外部- 实用性观点:更_itertools.one 函数在单元测试中可简化代码,避免异常处理。
- 库推荐:提到了“boltons”库,建议查看。
- 标准库讨论:希望 more_itertools 能成为标准库的一部分。
- 库功能:强调 more_itertools 提高了 Python 编程效率。
- 添加到 stdlib:讨论了将库添加到 Python 标准库的可能性。
- itertools 设计:对 itertools 的设计提出了一些不满。
- 性能比较:讨论了使用 more-itertools 与 pandas/numpy 之间的性能权衡。
- Pandas 讨论:关于 Pandas 数据框的类型检查和维护性讨论。
- Python 启动时间:指出 numpy 和 pandas 可能会增加 Python 启动时间。
- 异步迭代器:提到了 JavaScript 中的异步迭代器提案。